Slides
This module is also available in the following versions
Subject Overview: COMP90054 AI Planning for Autonomy
Weekly Lectures
Short videos covering background knowledge (in place of one 1 hour lecture)
watch before attending live lecture include questions
Live in-person lecture : Question & Answer, polls, and worked examples
Tutorials (Workshops)
Tutorials (workshops) start in week 1 (Friday)
Practice Quizzes (ungraded self-assessment)
Assignments
Individual project : Search + modelling a planning problem
Mid-semester test : Short quiz
Individual project : Reinforcement Learning
Marking: Ungrading + standards
Assessment flexibility: Tokens
Token Participation Streak = Engagement Flexibility
Streak = consecutive weekly lecture participation .
You can “spend” tokens for assignment extensions (1 token = ½ day extension)
If you miss a live lecture you can freeze the streak (1 token)
Your token budget = 2 tokens + max streak (weekly PollEv participation)
We encourage agency and responsibility,
are using less rigid policies, and
focus on learning instead of point-chasing (this is the ungrading approach).
Tokens adds structure and flexibility
Clear, fair, and manageable, and
no need to justify every request.
Things You Should Know to Enjoy this Subject
Algorithms such as Dynamic Programming
Basic Set Theory and Propositional Logic
Probabilistic Theory such as Conditional Probabilities
Python - start by doing a tutorial to refresh your knowledge
Importantly, you need to stay up to date reviewing and understanding the content, as most lectures build on previous knowledge.
Introduction to Python
You need to be confident programming in Python. Test your skills, refresh your knowledge or get up to speed doing these tutorials:
Introduction to probability theory
Consultation
If you don’t understand…or have a question…
\(\rightarrow\) Use Ed Discussion forum: COMP90054 Semester 1
Readings
COMP90054 Reinforcement Learning page - includes readings for each module and slides from live lectures
Primary Textbooks
Classical Planning
Reinforcement Learning
The reinforcement learning slides contain examples and material adapted with kind permission from David Silver, from Reinforcement Learning Slides which are licensed under the Creative Commons license CC BY-NC 4.0 . The version of reinforcement learning slides here are also covered under the same license.
Additional Text
Introduction to Search
Learning & Planning
Learning & Planning
Two fundamental problems in sequential decision making
Planning:
A model of the environment is known
The agent performs computations with its model (without any external interaction)
The agent improves its behaviour (policy ) through search, deliberation, reasoning, and introspection
Reinforcement Learning (RL):
The environment is initially unknown
The agent interacts with the environment
The agent improves its policy (behaviour)
Examples
Making a humanoid robot walk
Fine tuning LLMs using human/AI feedback
Optimising operating system routines
Controlling a power station
Managing an investment portfolio
Competing in the International Mathematical Olympiad
Multi-agent pathfinding by robots in a warehouse
Example: Make a humanoid robot walk
VIDEO
Atlas demonstrates policies using RL based on human motion capture and animation - Boston Dynamics 2025 youtube.com/watch?v=I44_zbEwz_w
Example: Fine tuning LLMs using human/AI feedback
VIDEO
Proximal policy update (PPO) used by ChatGPT 3.5 & Agentic AI - Chat GPT ‘Operator’ & Claude’s ‘Computer Use’ modes. youtube.com/watch?v=VPRSBzXzavo
VIDEO
Group relative policy optimisation (GRPO) (more stable than PPO) used in DeepSeek’s latest models.
youtube.com/watch?v=xT4jxQUl0X8
Example: Optimising operating system routines
2023, Daniel J. Mankowitz, et al. Faster sorting algorithms discovered using deep reinforcement learning, Nature , Vol 618, pp. 257-273
DeepMind’s AlphaDev , a deep reinforcement learning agent, has discovered faster sorting algorithms, outperforming previously known human benchmarks.
The sort routine is called up to a trillion times a day worldwide
These newly discovered algorithms have already been integrated into the LLVM standard C++ sort library .
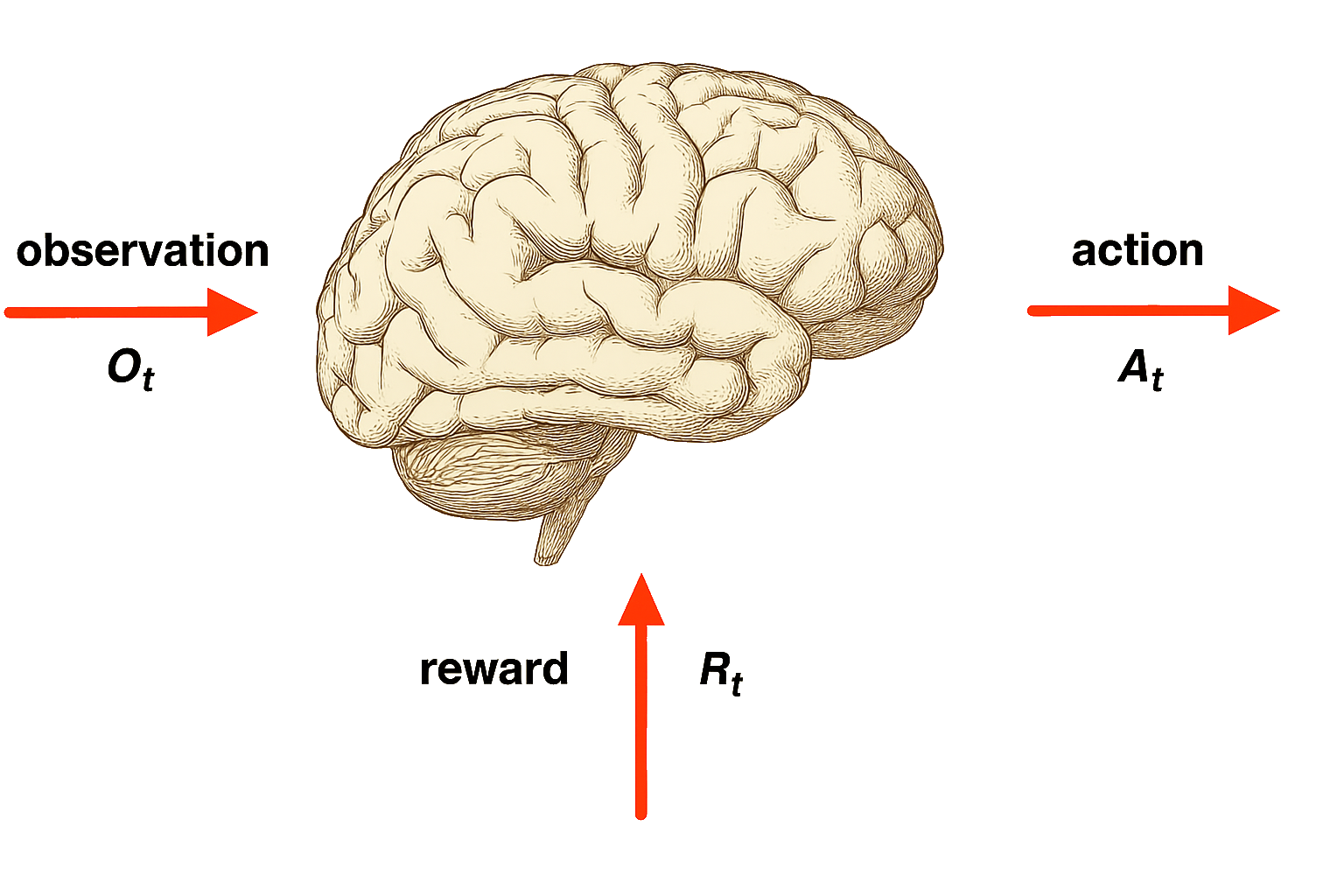
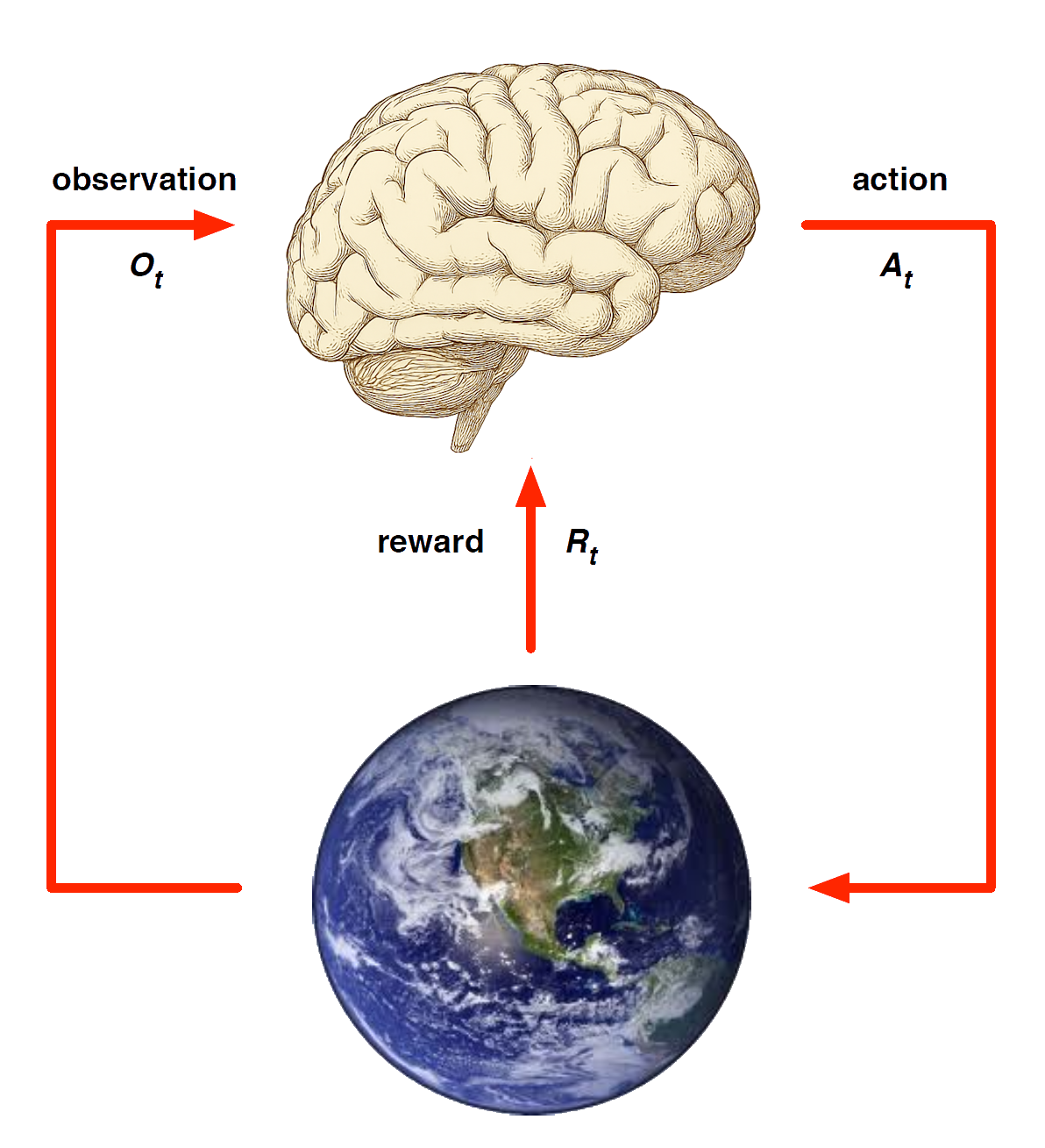
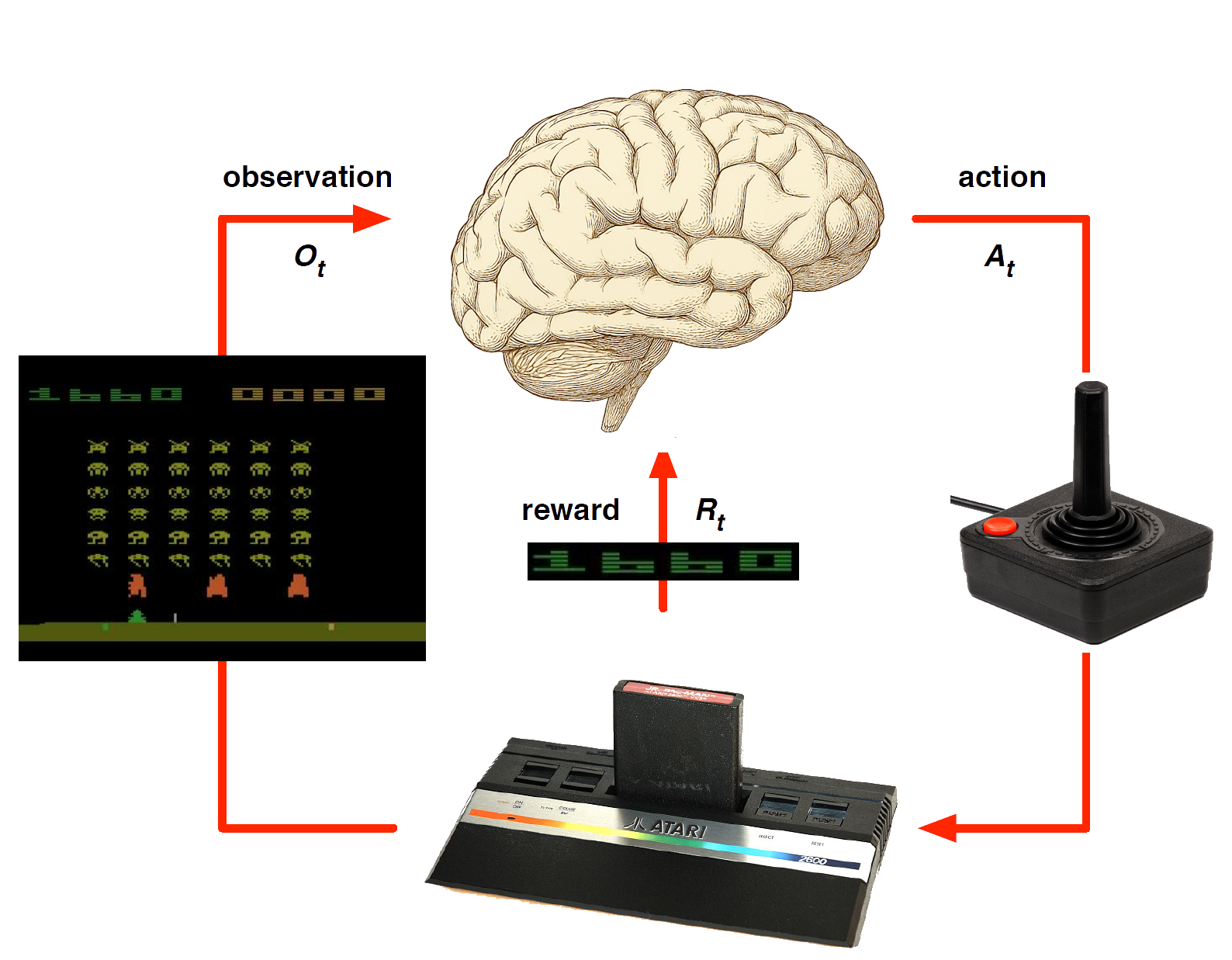
Agent model
Agent and Environment
At each step \(t\) the agent:
The environment:
Receives action \(A_t\)
Emits observation \(O_{t+1}\)
Emits scalar reward \(R_{t+1}\)
\(t\) increments at env. step
History and State
The history is sequence of observations, actions, rewards
\[
H_t = O_0,R_0,A_0, \ldots A_{t-1}, O_t, R_t
\] - i.e. the stream of a robot’s actions, observations and rewards up to time \(t\)
What happens next depends on the history:
The agent selects actions, and
the environment selects observations/rewards.
State is the information used to determine what happens next.
Formally, a state is a function of the history: \(S_t = f(H_t )\)
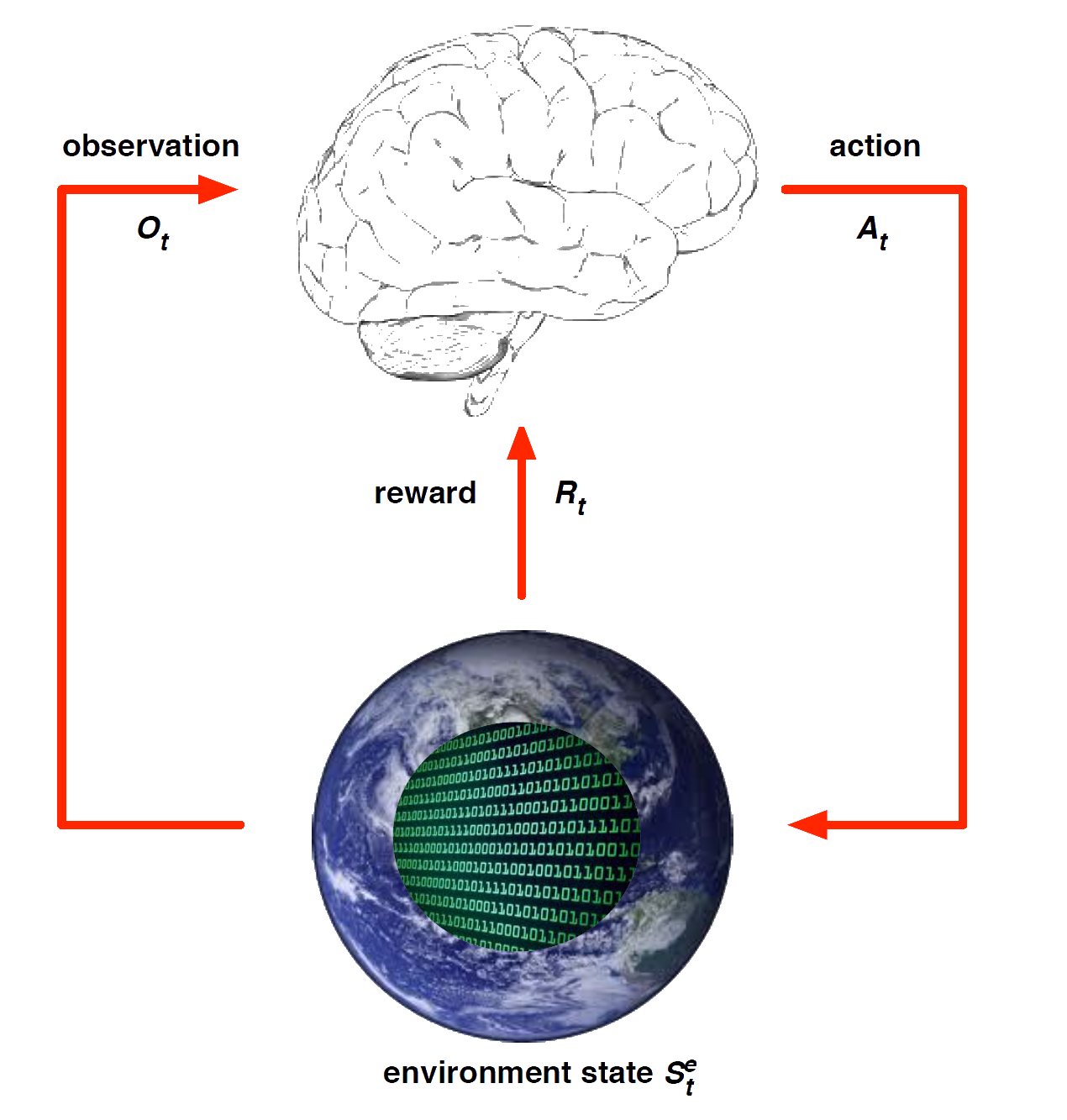
Environment State
The environment state \(S^e_t\) is the environment’s private representation
i.e. environment uses to determine the next observation/reward
The environment state is not usually visible to the agent
Even if \(S^e_t\) is visible, it may contain irrelevant info
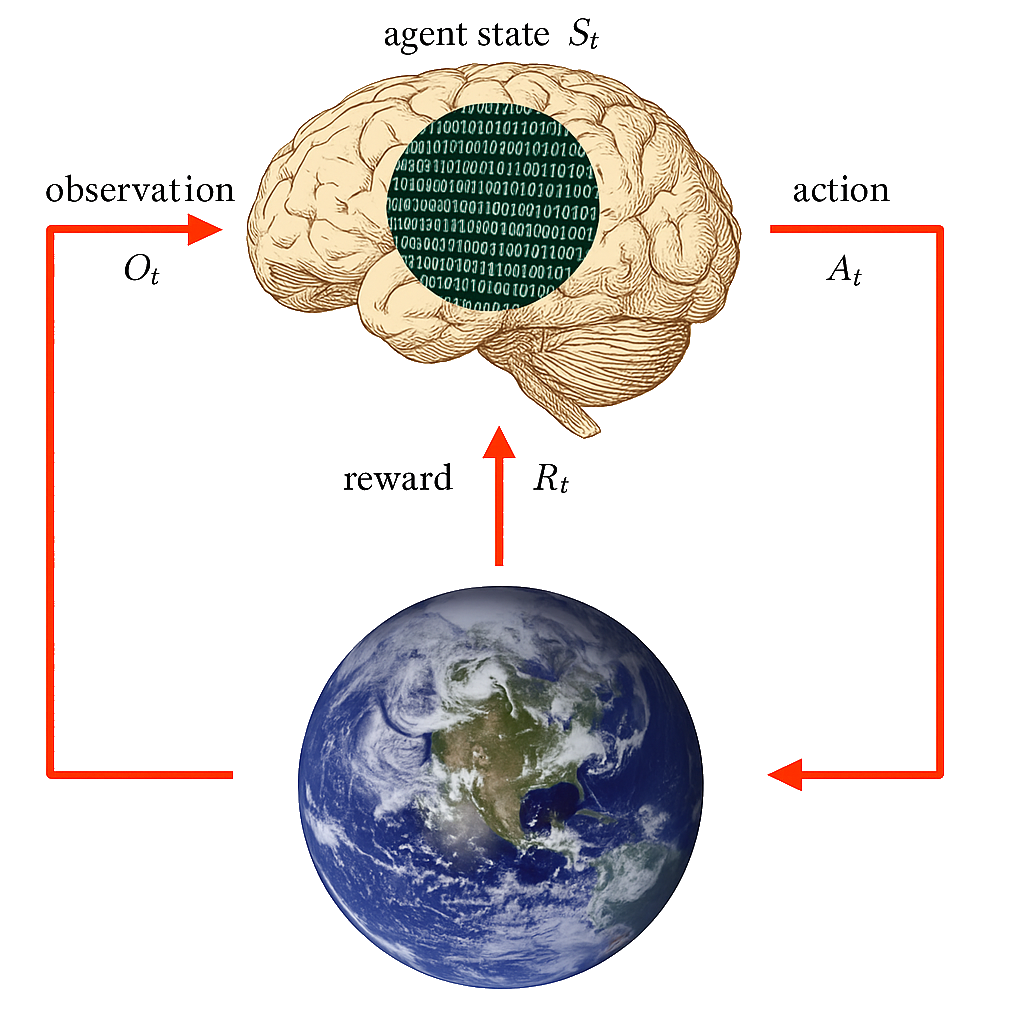
Agent State
The agent state \(S^a_t\) is the agent’s internal representation
It can be any function of history: \(S^a_t = f(H_t)\)
Patience Example: Classical Planning
States : Card positions (position Jspades=Qhearts).Actions : Card moves (move Jspades Qhearts freecell4 ).Initial state : Start configuration.Goal (reward) states : All cards ‘home’.Solution : Card moves solving this game.
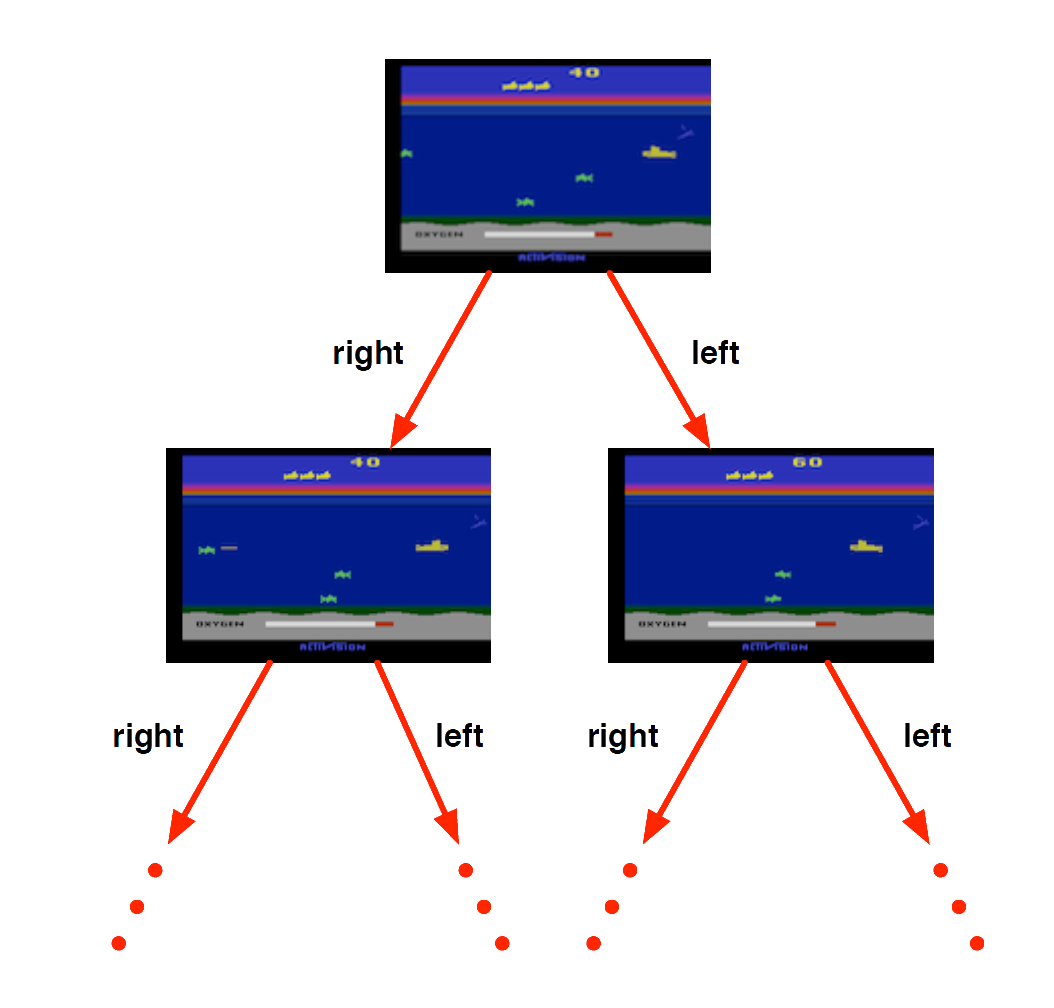
Atari Example: Planning
If rules of the game are known
perfect model inside agent’s brain
If I take action \(a\) from state \(s\) :
Plan ahead for reward - stay alive, maximise score!
Atari Example: Learning
If rules of the game are unknown
Pick joystick actions, only see pixels & scores
Learn directly from interactive game-play
Rewards & Goals
Rewards & Goals
A reward \(R_t\) is a scalar feedback signal.
Indicates how well agent is doing at step \(t\)
The agent’s job is to maximise cumulative reward
Reinforcement learning is based on the reward hypothesis
All goals can be described by the maximisation of expected cumulative reward.
Example of Rewards
Make a humanoid robot walk
-ve reward for falling
+ve reward for forward motion
Optimise sort routine in an operating system
-ve reward for execution time
+ve reward for throughput
Control plasma in a stellarator in a fusion power station
+ve reward for containment of plasma
-ve reward for plasma crashing
Control inventory in a warehouse
-ve reward for stock-out penalty (lost sales)
-ve reward for holding costs (inventory)
+ve reward for sales revenue
Sequential Decision Making
Goal: select actions to maximise total future reward
Examples:
Markov State
Markov State
A Markov state (a.k.a. Information state) contains all useful information from the history.
A state \(S_t\) is Markov if and only if \[
\mathbb{P} [S_{t+1} | S_t ] = \mathbb{P} [S_{t+1}\ |\ S_0, \ldots, S_t ]
\]
Markov states are key to both planning and learning
Markov State (continued)
Once the state is known, the history may be thrown away, i.e. The state is a sufficient statistic of the future
How is a Markov state dependent on time - in terms of the past, present and future?
“The future is independent of the past given the present” \[
H_{1:t} \rightarrow S_t \rightarrow H_{t+1:\infty}
\]
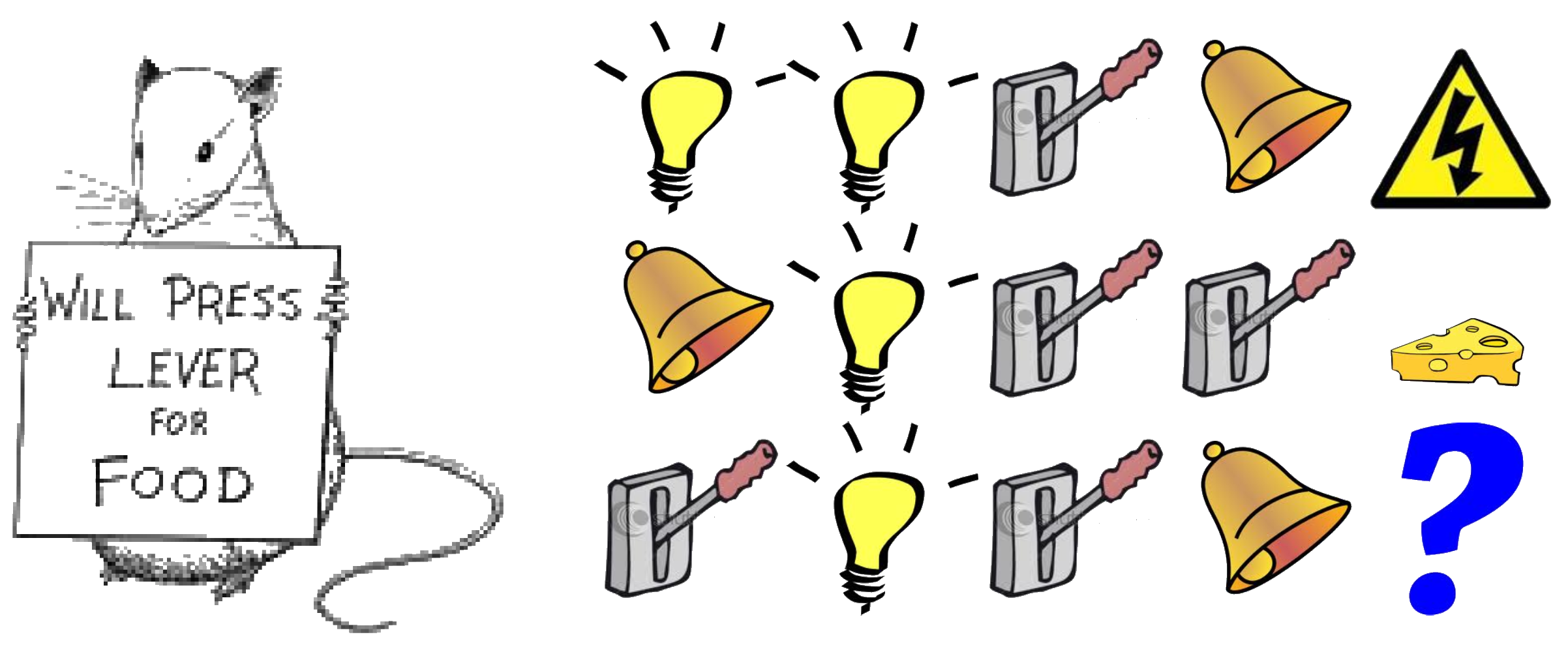
Rat Example
- What if agent state = last \(3\) items in sequence?
Shock
- What if agent state = counts for lights, bells and levers?
Cheese
- What if agent state = complete sequence?
?
Components of an Agent
What are the components of a Markov planning and learning agent?
Example to help you think about question:
Components of an Agent
What are the components of a Markov planning and learning agent?
An agent may include one or more of these components:
Policy: agent’s behaviour function
Value function: how good is each state and/or action (rewards/goals)
Model: agent’s representation of the dynamics of the environment (including states, propositions (STRIPS) and/or probabilities (MRPs)
Policy
A policy is the agent’s behaviour
It is a map from state to action, e.g.
Value Function
Value function is a prediction of future reward
Used to evaluate the goodness/badness of states, and
therefore to select between actions, e.g.
\[
v_{\pi}(s) = \mathbb{E}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots | S_t = s]
\]
Model
A model predicts what the environment will do next
\(\mathcal{P}\) predicts the probability of the next state
\(\mathcal{R}\) predicts the expectation of the next reward , e.g.
\[
\mathcal{P}^a_{ss'} = \mathbb{P}[S_{t+1} = s' | S_t = s, A_t = a]
\]
\[
\mathcal{R}^a_s = \mathbb{E}[R_{t+1} | S_t = s, A_t = a]
\]
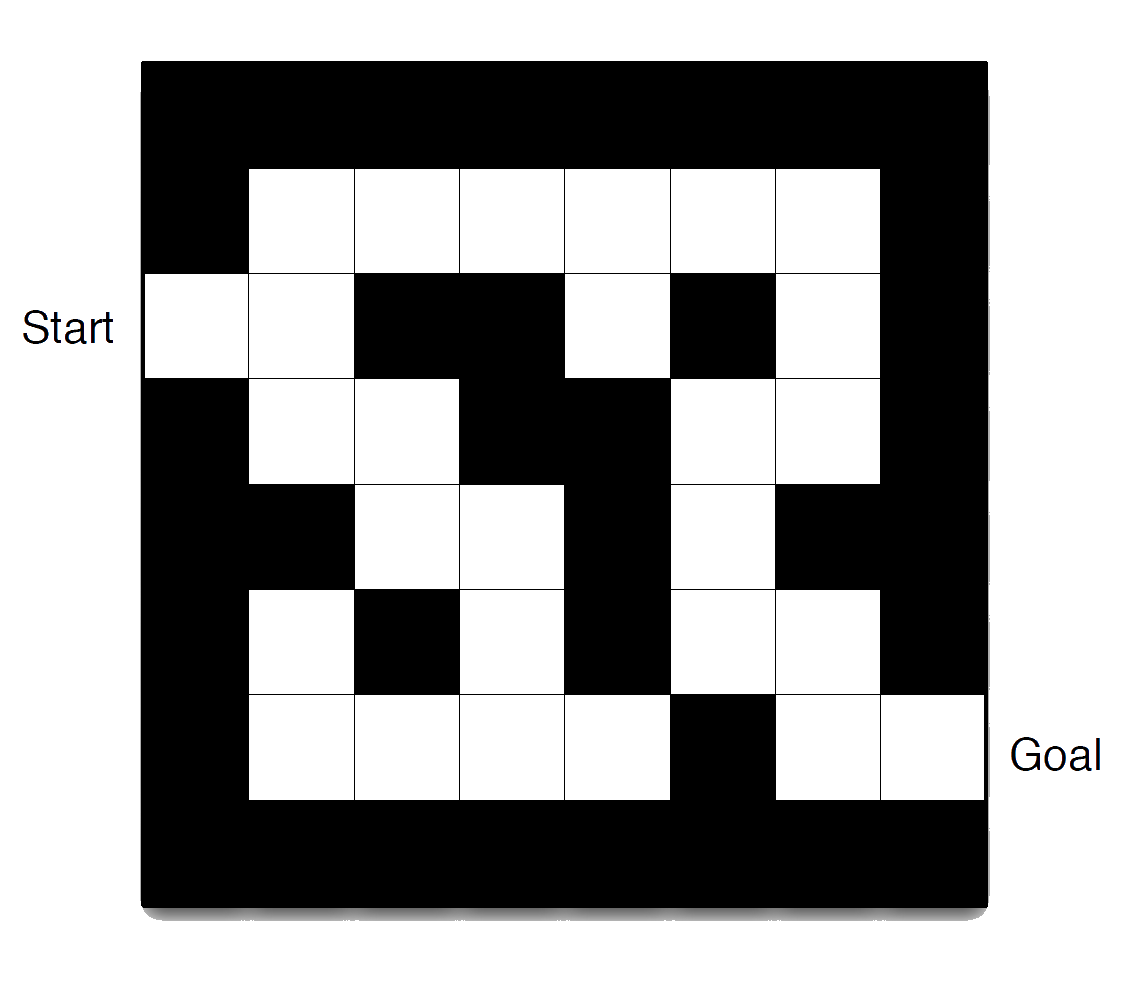
Maze Example
Rewards: -1 per time-step
Actions: N, E, S, W
States: Agent’s location
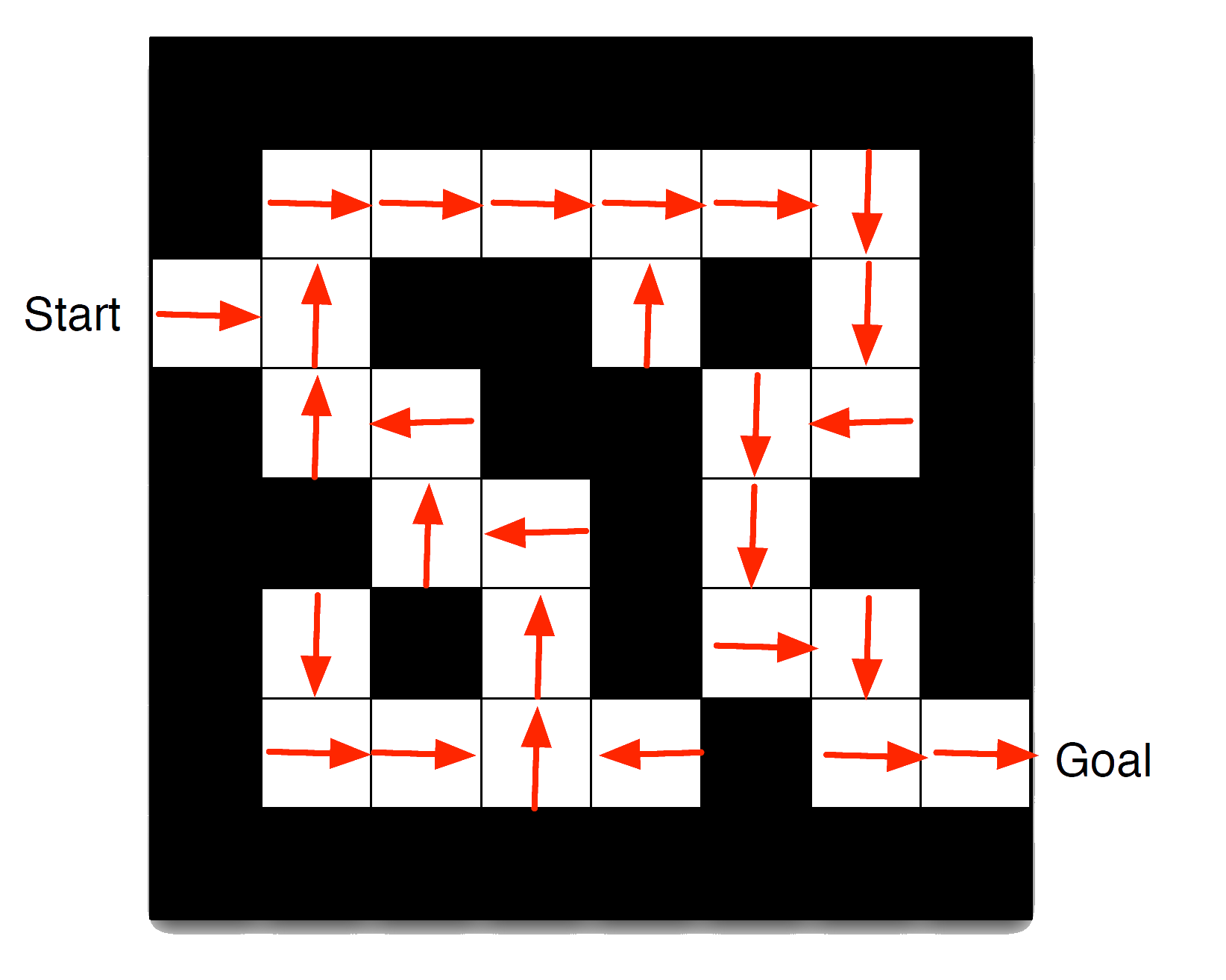
Maze Example: Policy
Arrows represent policy \({\color{red}\pi(s)}\) for each state \(s\)
Maze Example: Value Function
Numbers represent value \(v_{\pi}(s)\) of each state \(s\)
Maze Example: Model
Agent may have an internal model of the environment
Dynamics: how actions change the state
Rewards: how much reward from each state
The model may be imperfect
Grid layout represents transition model \(\mathcal{P}^a_{ss'}\)
Numbers represent immediate reward \(\mathcal{R}^a_s\) from each state \(s\) (same for all \(a\) )
Goals and Rewards
Classical planning typically relies on a model
The agent aims to synthesise a plan toward achieving a goal
A plan is a special case of a policy (for one set of initial conditions) toward achieving a goal.
The goal is a special case of (more general) value achieved from reward.
Exploration and Exploitation
Reinforcement learning is like trial-and-error learning
The agent should discover a good policy…
…from its experiences of the environment…
…without losing too much reward along the way.
Exploration and Exploitation (continued)
Exploration finds more information about the environment
Exploitation exploits known information to maximise reward
It is usually important to explore as well as exploit
Examples
Restaurant SelectionExploitation Go to your favourite restaurantExploration Try a new restaurant
Online Banner AdvertisementsExploitation Show the most successful advertExploration Show a different advert
Gold explorationExploitation Drill core samples at the best known locationExploration Drill at a new location
Examples (continued)
Game PlayingExploitation Play the move you believe is bestExploration Play an experimental move
Prediction and Control
Prediction : evaluate the future
Control : optimise the future
We need to solve the prediction problem in order to solve the control problem
i.e. we need evaluate all of our policies in order to work out which is the best one
Characteristics of Classical Planning & Reinforcement Learning
It is helpful to think about the differences:
What makes planning different from traditional machine learning paradigms?
Sequence matters, i.e. it involves non-i.i.d. (independent and identically distributed) data
…contemporary deep learning utilises sequence too, through e.g. attention based transformers
What makes reinforcement learning different from other machine learning paradigms?
There is no supervisor, only a reward signal
Feedback is delayed, not instantaneous
…contemporary transformers utilise RL techniques (ChatGPT, DeepSeek, etc.)
What makes reinforcement learning different from planning?
The outcomes of actions are non-deterministic
Uses probabilistic representation
Relies on (more general) rewards instead of goals