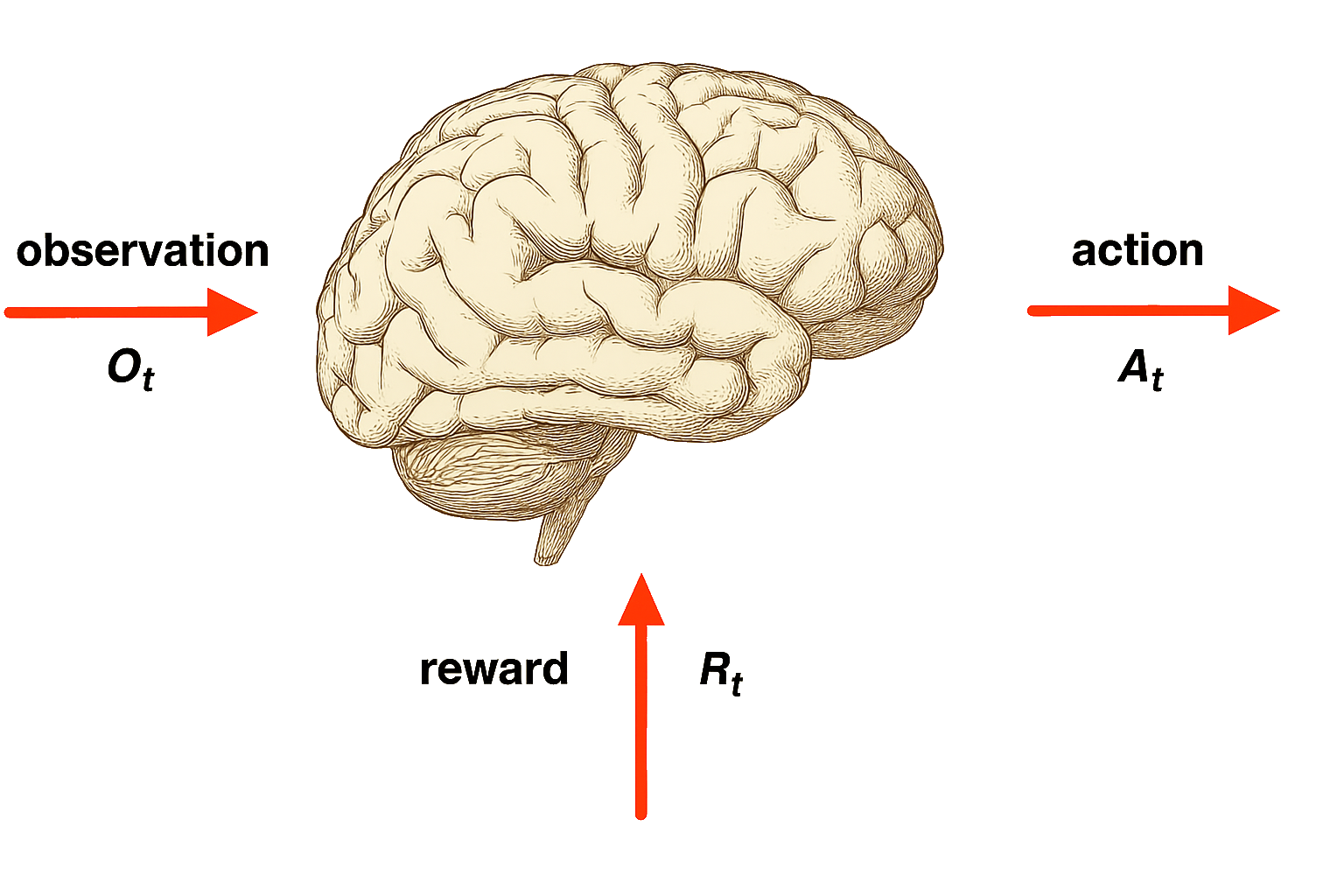
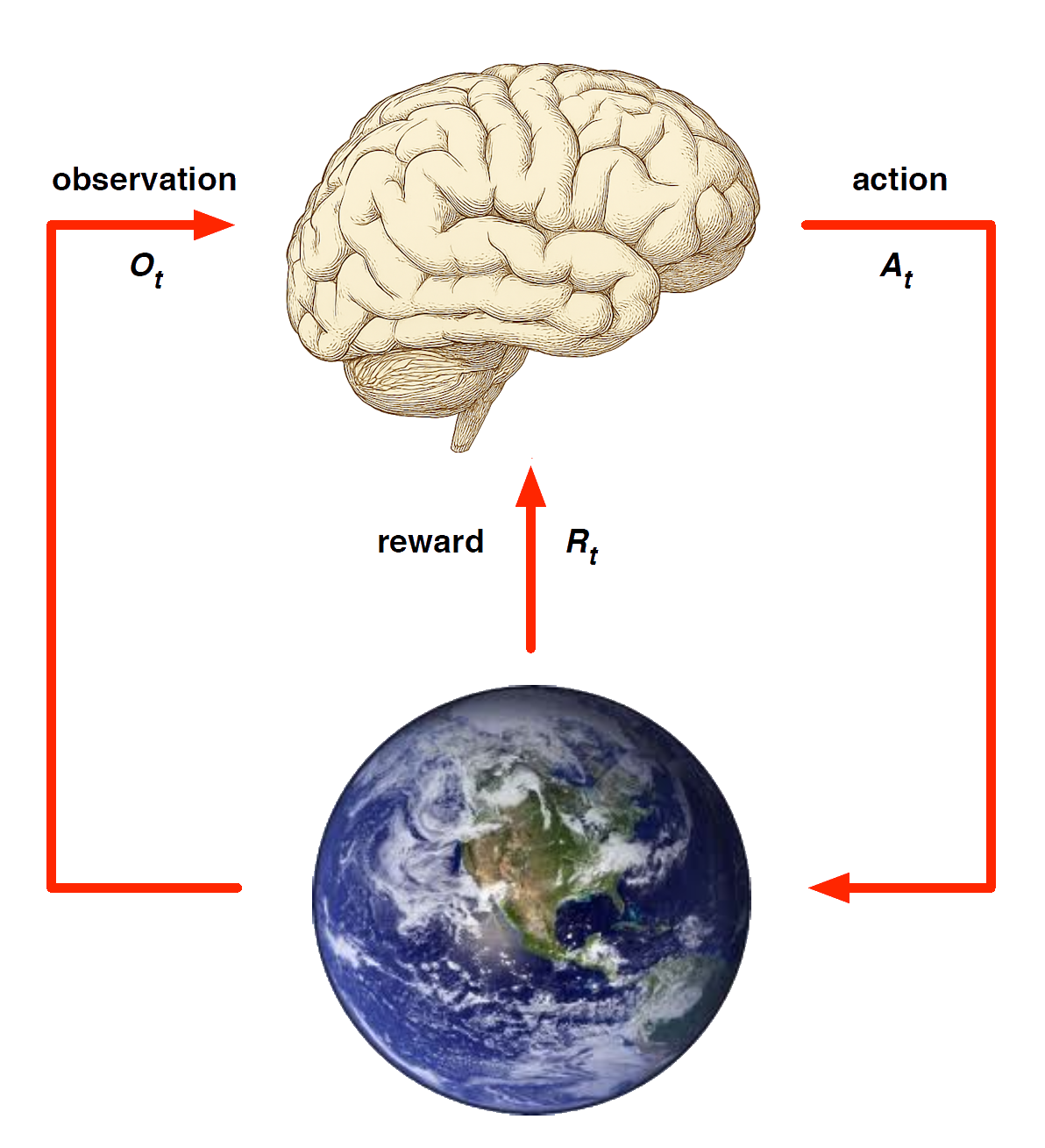
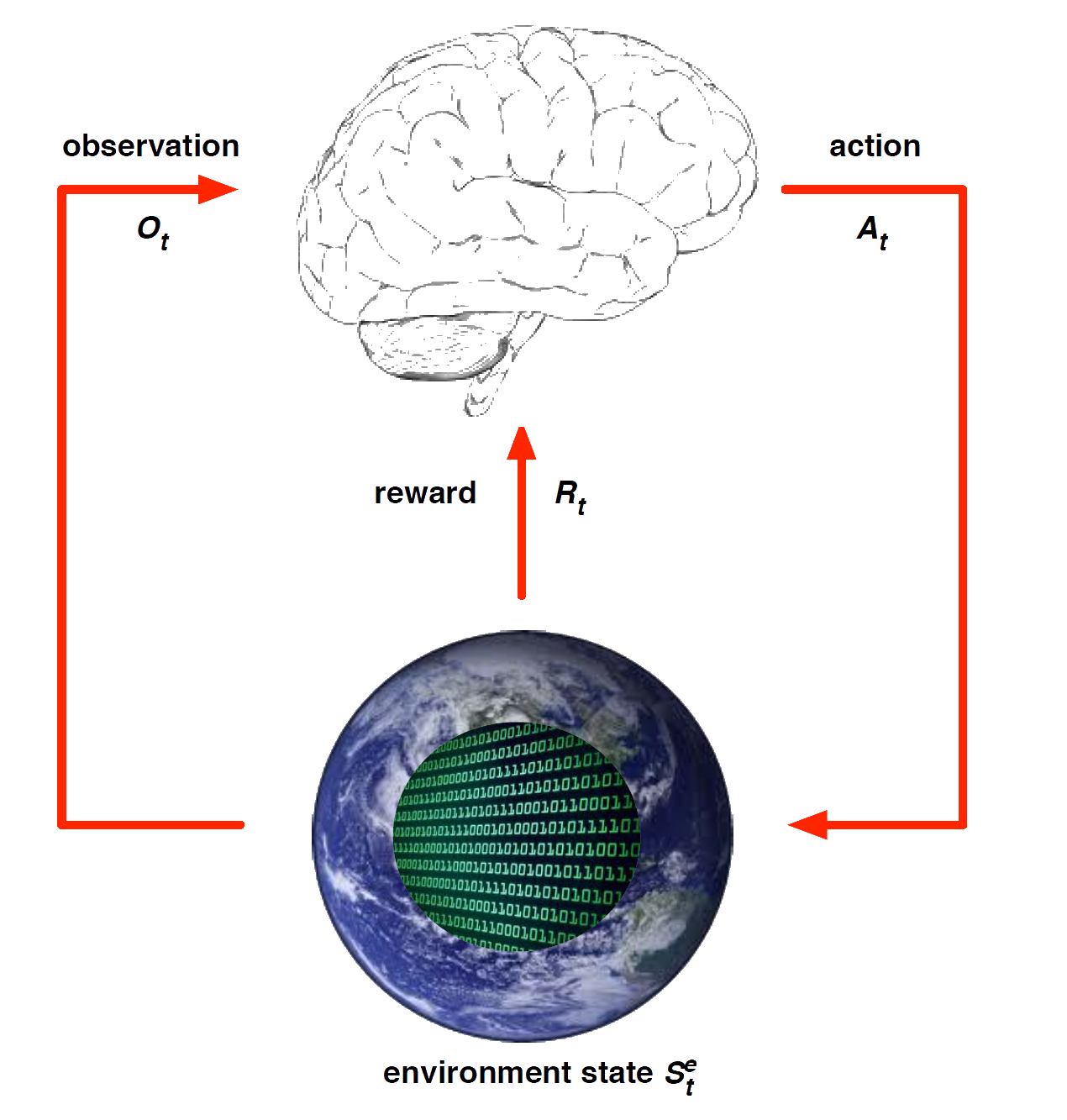
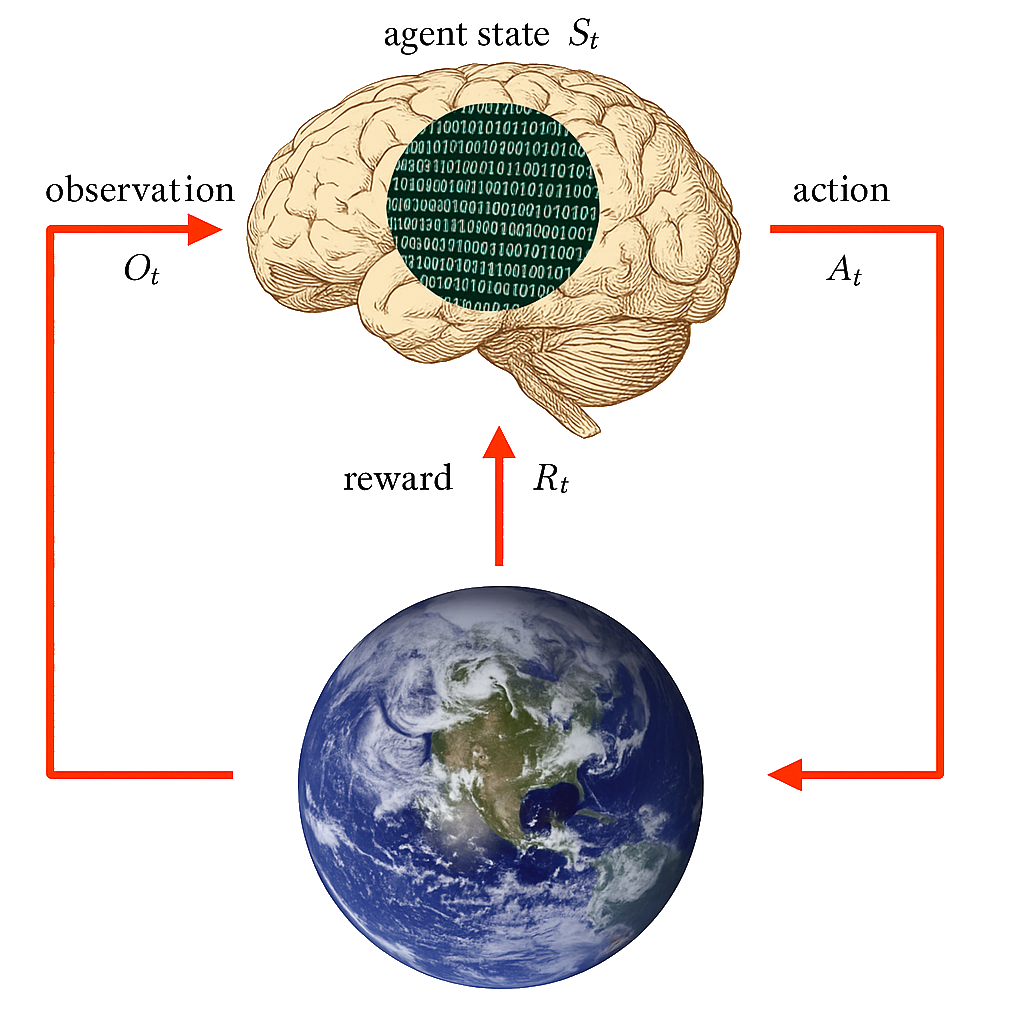
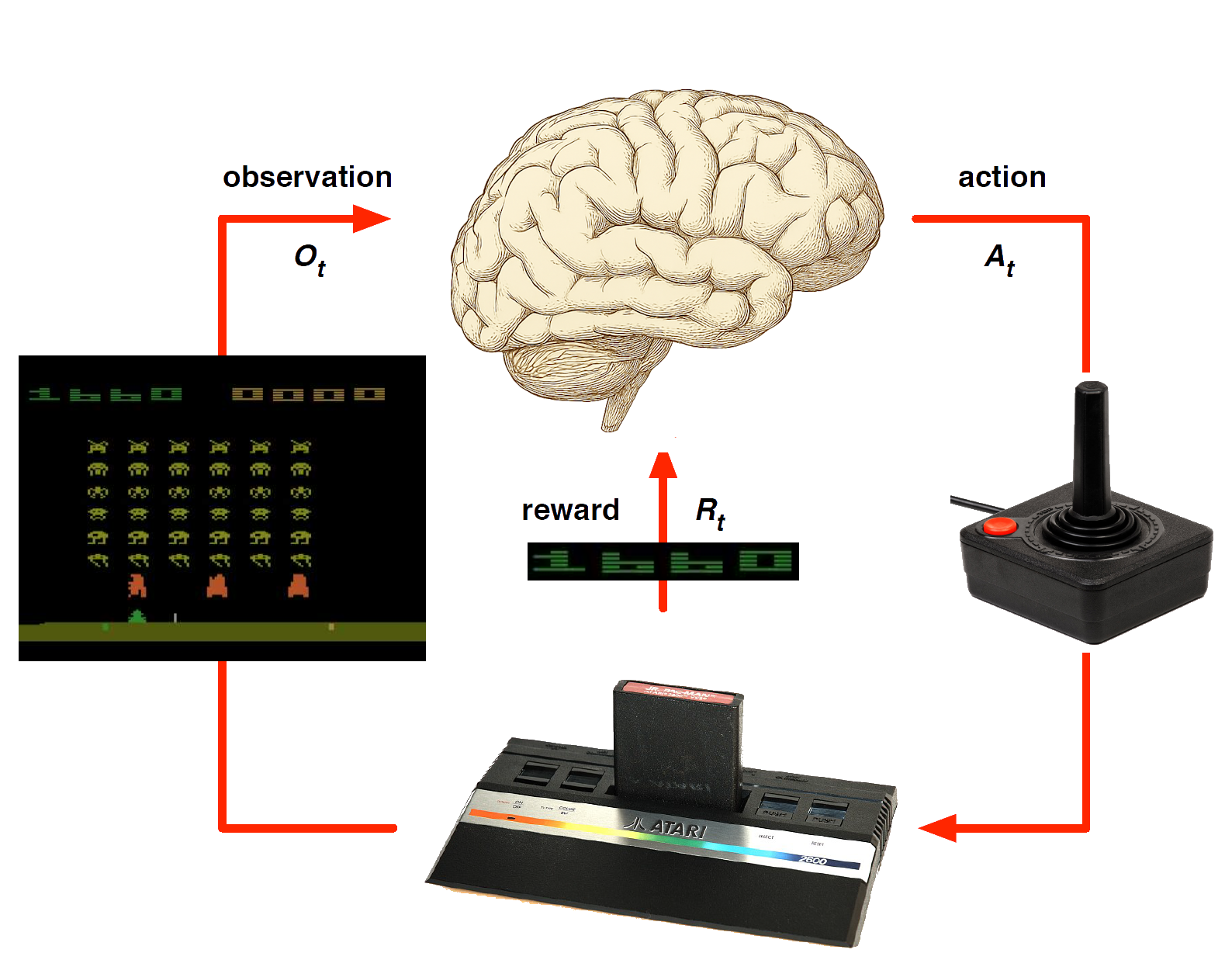
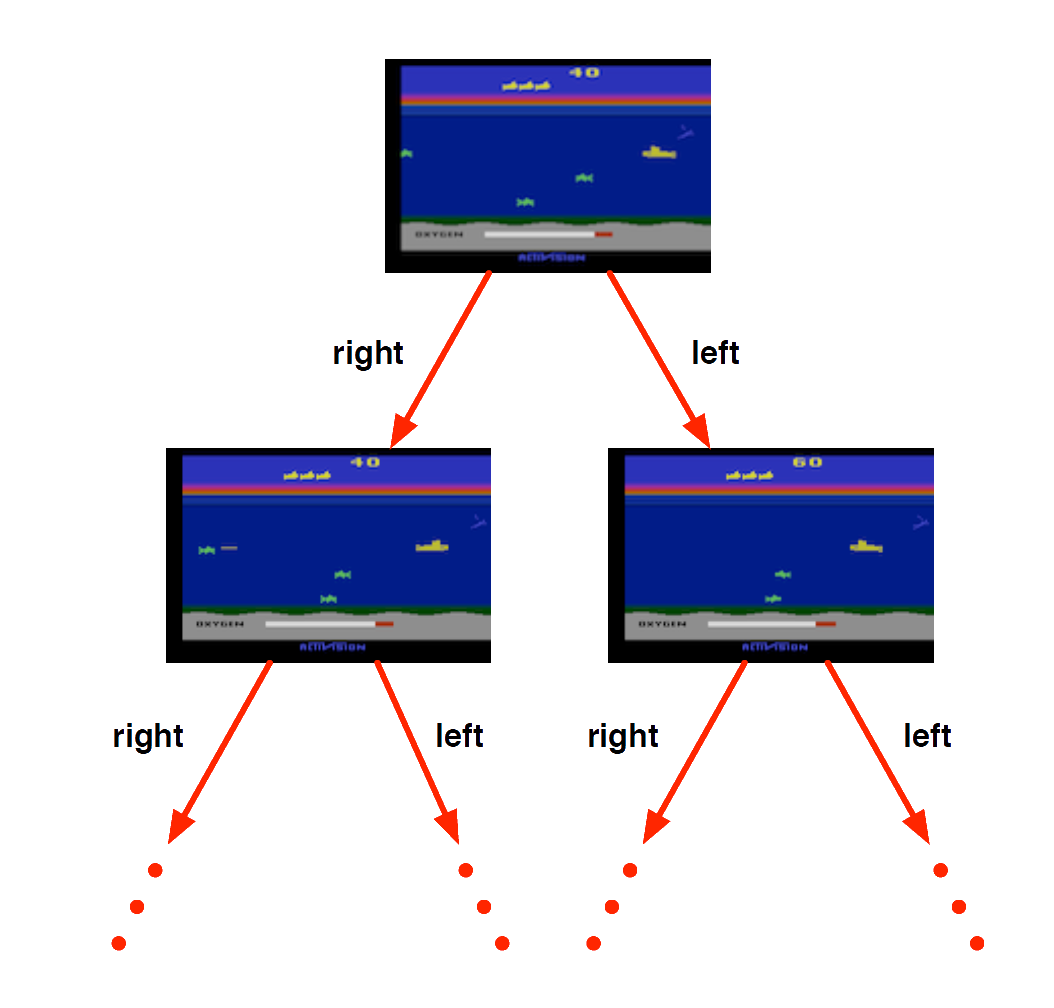
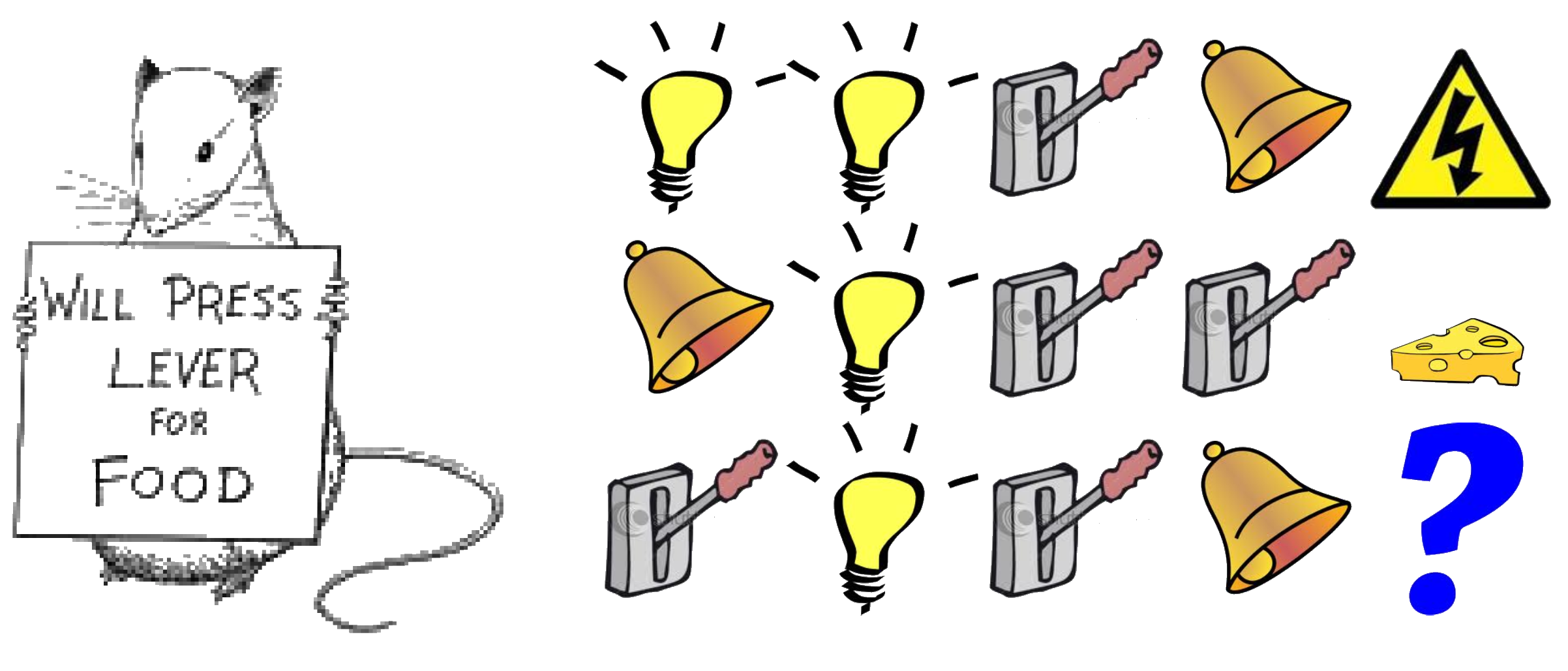
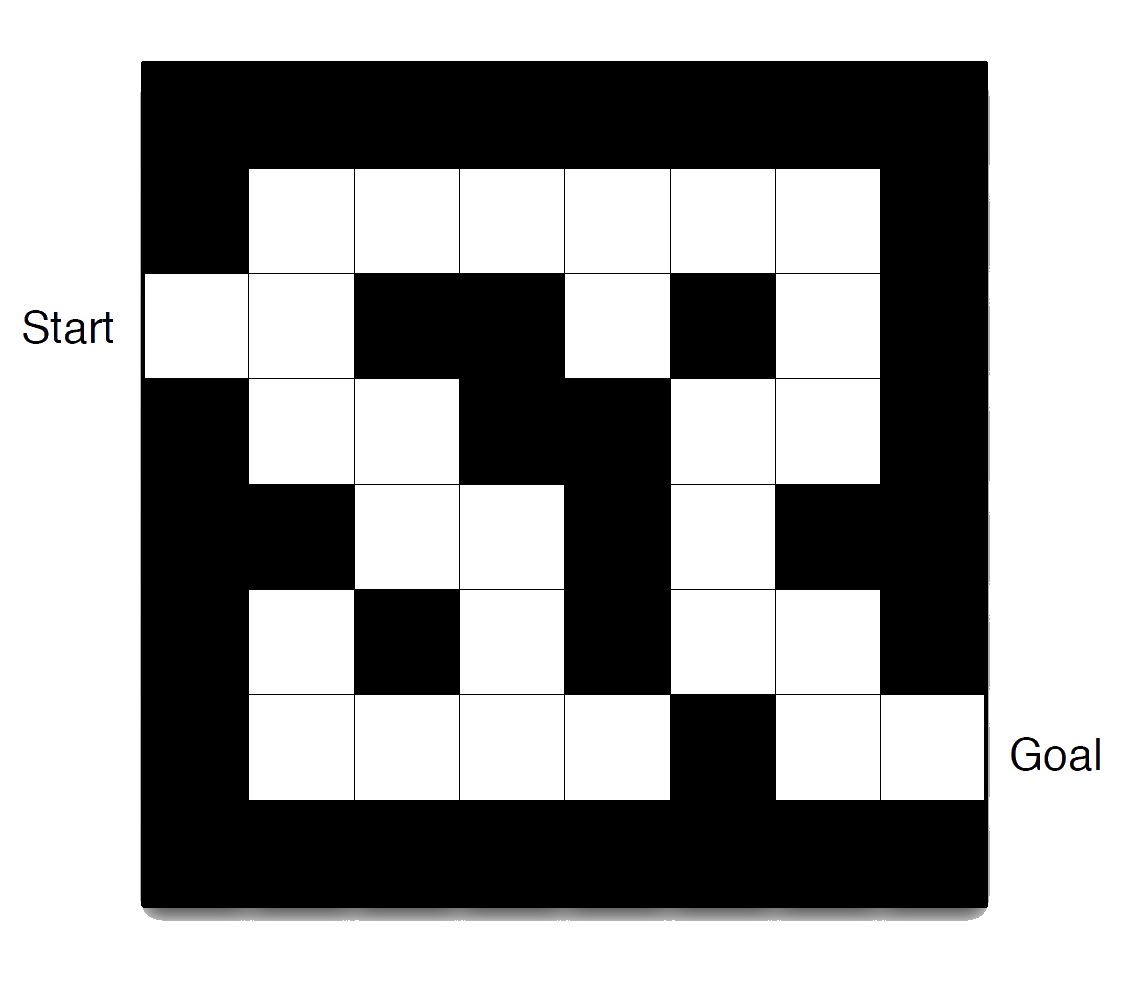
Primary Textbooks
Classical Planning
- A Concise Introduction to Models and Methods for Automated Planning, Hector Geffner and Blai Bonet, Springer Nature (2013) - available via institutional (University of Melbourne) login
- An Introduction to the Planning Domain Definition Langauge, Patrik Haslum, Nir Lipovetzky, Daniele Magazzeni, and Christian Muise, Springer (2019) - available via institutional login