07 Model-Free Prediction (Bandit Strategies + MC learning)
Multi-armed bandits
Intuition: For every state \(s\), each action \(a\) = slot machine with initually unknown payoff distributions \(X_{a}\).
The “value” \(Q(s, a)\) of \(a\) corresponds to (current estimate of) \(X_{a}\).
\[ Q_t(a, s) = \frac{R(a, t)}{N(a,s, t)} \]
where \(N(a, s, t) =\) the number of times action \(a\) has been performed in state \(s\) at time \(t\), and \(R(a, t)\) is the total reward earned from those actions as of time \(t\).
\(\epsilon\)-greedy
with probability \(1 - \epsilon\), choose the arm with maximum \(Q\)-value (exploit)
with probability \(\epsilon\), choose arm uniformly at random (explore)
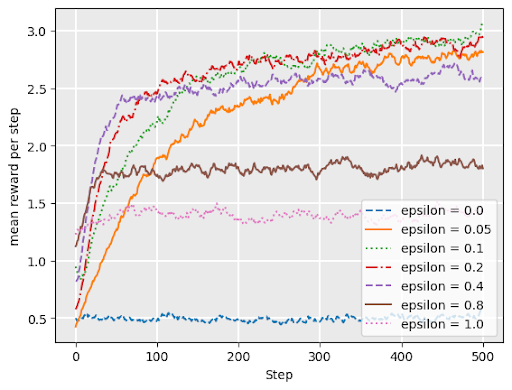
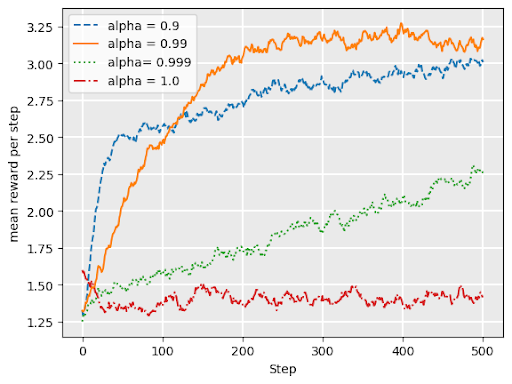
\(\epsilon\)-decreasing
Adds a variable \(\alpha\) = “decay”
\(0 < \alpha < 1\)
Like \(\epsilon\) greedy, but explore probability is \(\epsilon*\alpha^t\) at timestep \(t\)
Q: what does it mean for our exploration/ exploitation strategy for \(\epsilon\) to be larger (closer to 1)?
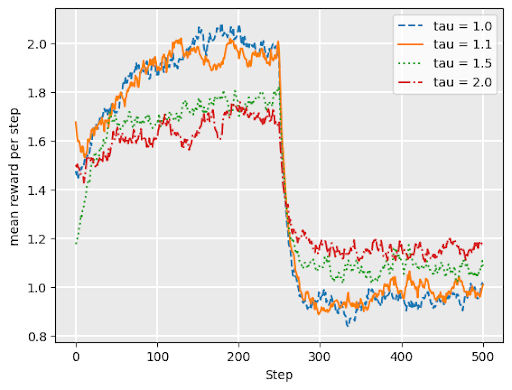
softmax continued
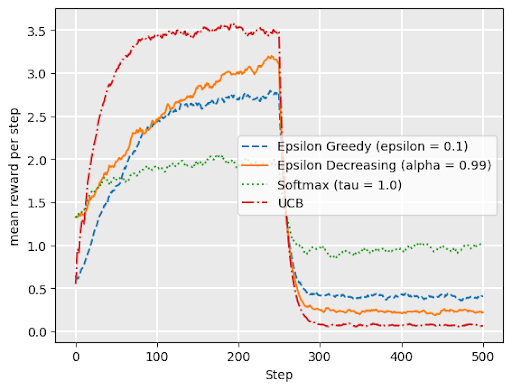
Softmax works well under drift– when underlying reward distributons change over time
Graph shows softmax performance for “restless bandit” where reward distributions abruptly change at \(t= 250\).
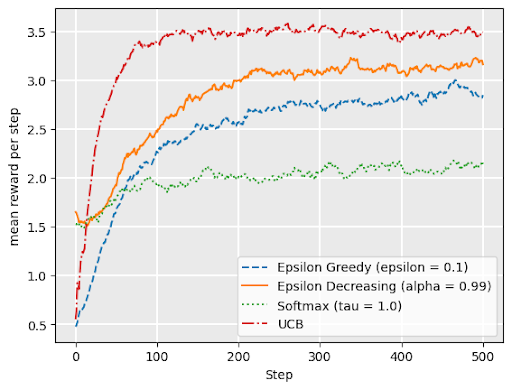
Comparing bandit strategies
no drift
drift
Q-tables
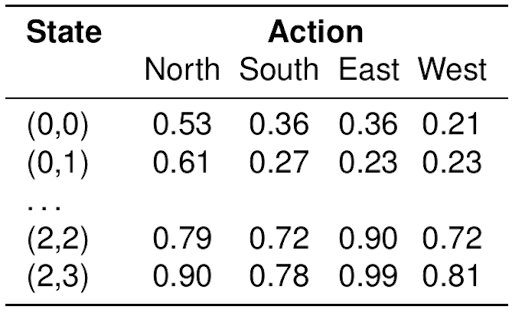
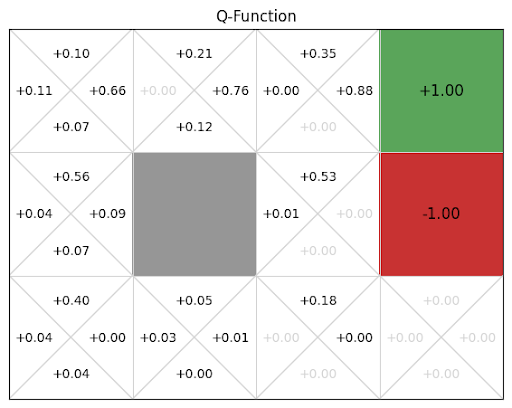
\(Q(s, a)\) indicates our current guess (observed average) for the long term expected discounted reward associated with taking action \(a\) in state \(s\)
Gridworld Example
Update \(Q\)-table (initialized to 0) based on this trajectory:
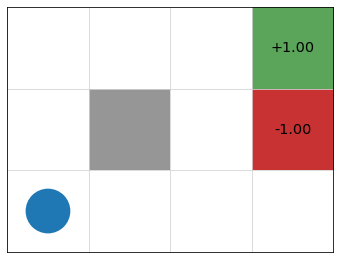
\(s_0 = (1, 1)\), \(a_0 =\) up, \(r_0 = 0\),
\(s_1 = (2, 1)\), \(a_1 =\) right, \(r_1 = 0\),
\(s_2 = (3, 1)\), \(a_2 =\) up, \(r_2 = 0\),
\(s_3 = (3, 2)\), \(a_3 =\) up, \(r_3 = 0\),
\(s_4 = (4, 2)\), \(a_4 =\) claim reward, \(r_4 = -1\).