05 Markov Decision Processes (MDPs)
Atari Example
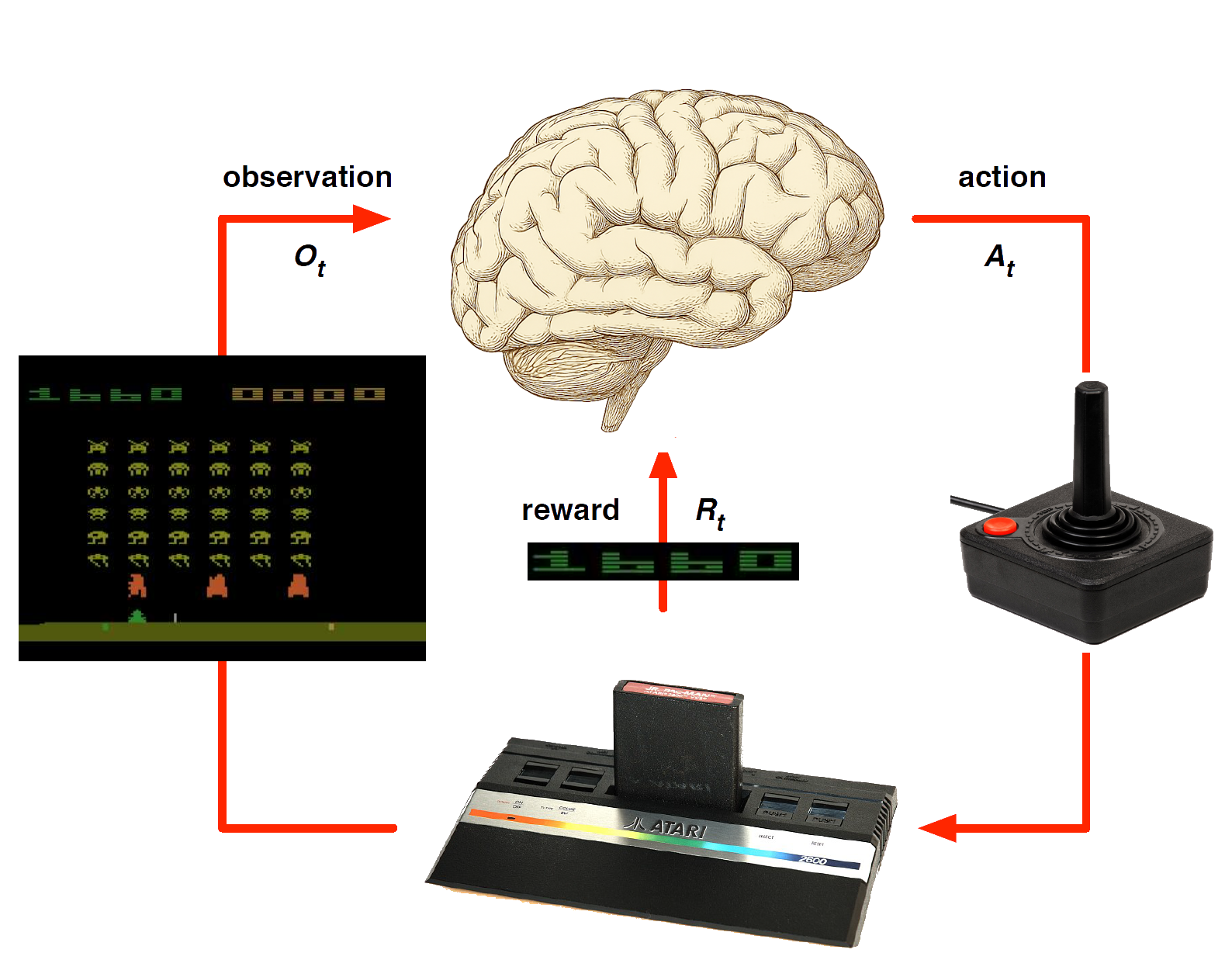
Atari Example: Planning
Rules of the game are known
Can query emulator (simulator)
- perfect model inside agent’s brain
If I take action \(a\) from state \(s\):
what would the next state \(s'\) be?
what would the score be?
Plan ahead to find optimal policy, e.g. heuristic tree search, novelty etc.
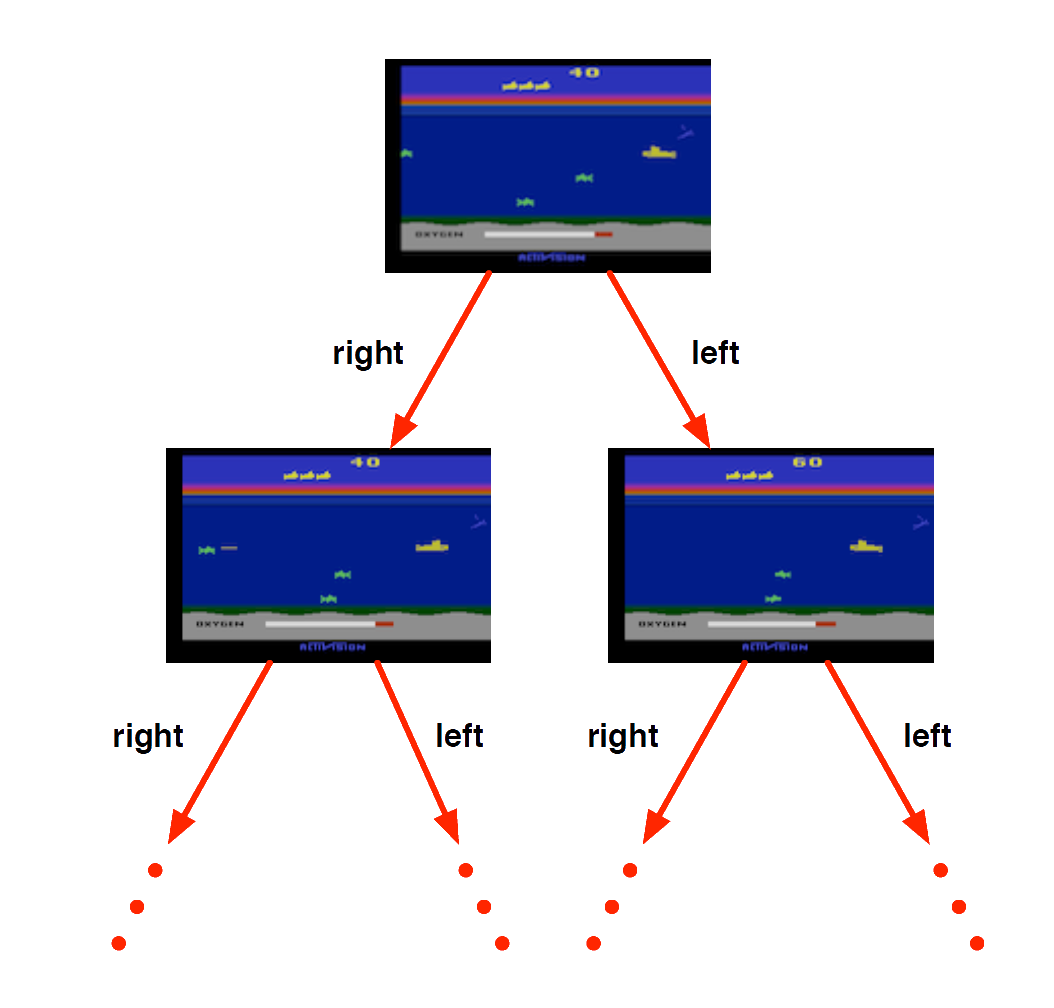
Atari Example (without emulator): Reinforcement Learning
Rules of the game are unknown
Pick joystick actions, only see pixels & scores
Learn directly from interactive game-play
Reward Hypothesis
Goals are characterised as the maximisation of expected cumulative reward.
Example: Gridworld
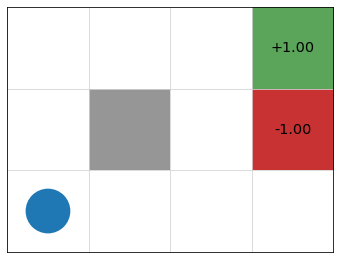
- states = cells
- actions = up, down, left, right, 10% chance of 90\(\degree\) error
- reward \(r(s) = 0\) for non-terminal nodes
- discount factor \(\gamma = 0.9\)
Episodes
An episode, history, or trajectory through an MDP is the sequence of states and actions that occur as an agent traverses an MDP.
Example:
state = (1, 1), (try to) go up,
state = (2, 1), go right,
state = (3, 1), go up,
state = (3, 2), (try to) go up
state = (4, 2) TERMINAL
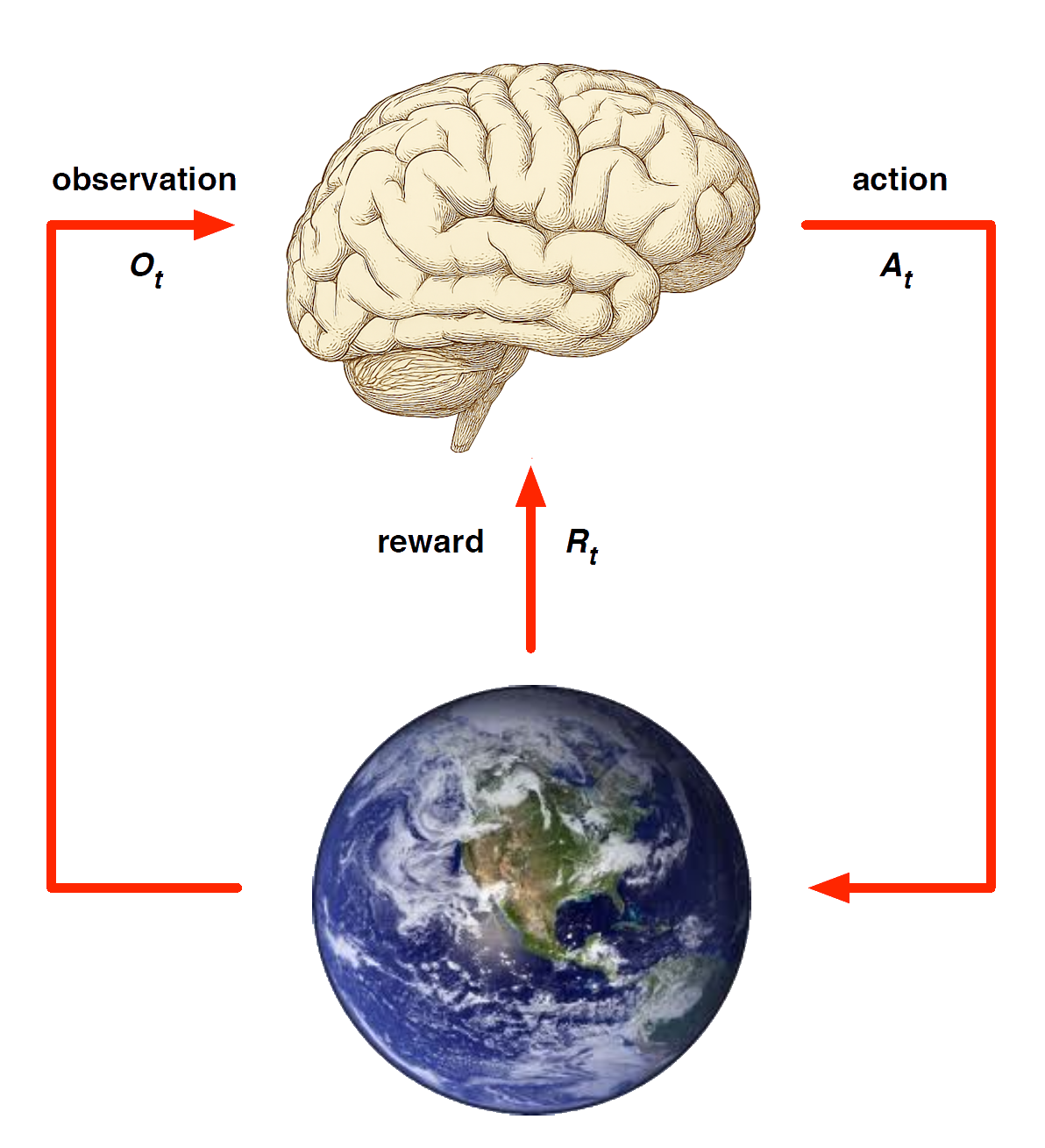
Agent and Environment
At each step \(t\) the agent:
Executes action \(A_t\)
Receives observation \(O_t\)
Receives scalar reward \(R_t\)
The environment:
Receives action \(A_t\)
Emits observation \(O_{t+1}\)
Emits scalar reward \(R_{t+1}\)
\(t\) increments at env. step
Environment State
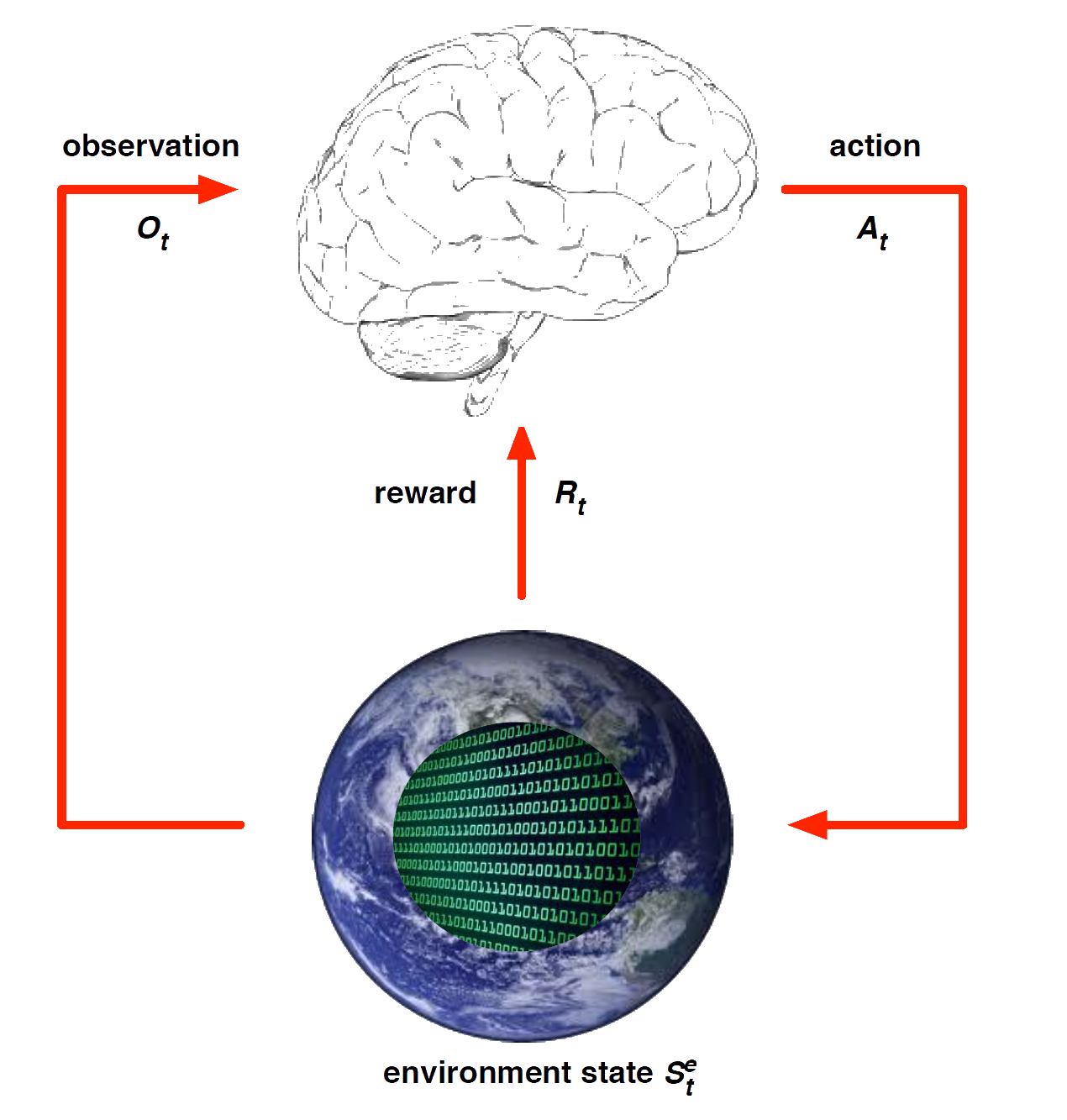
The environment state \(S^e_t\) is the environment’s private representation
- i.e. data environment uses to pick the next observation/reward
The environment state is not usually visible to the agent
- Even if \(S^e_t\) is visible, it may contain irrelevant info
Agent State
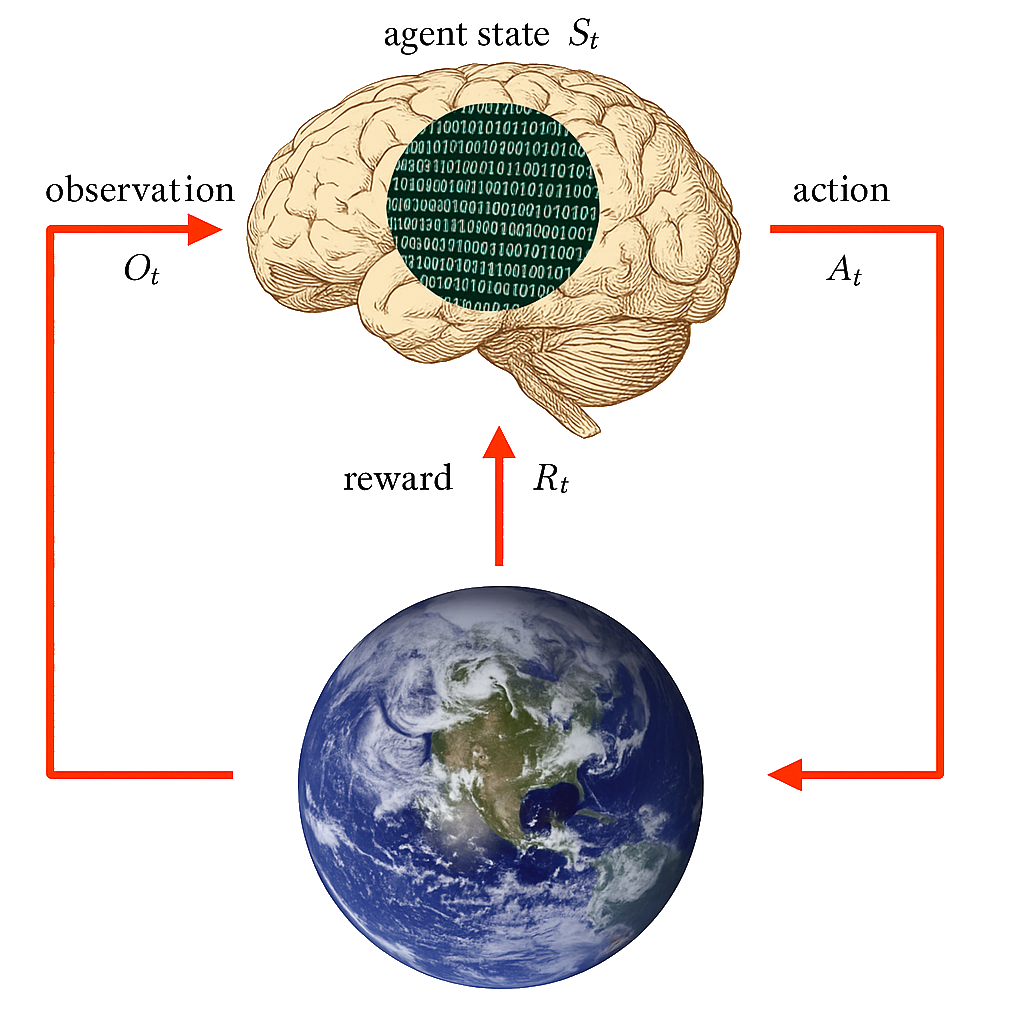
The agent state \(S^a_t\) is the agent’s internal representation
i.e. information the agent uses to pick the next action
i.e. information used by reinforcement learning algorithms
It can be any function of history: \(S^a_t = f(H_t)\)
Rat Example
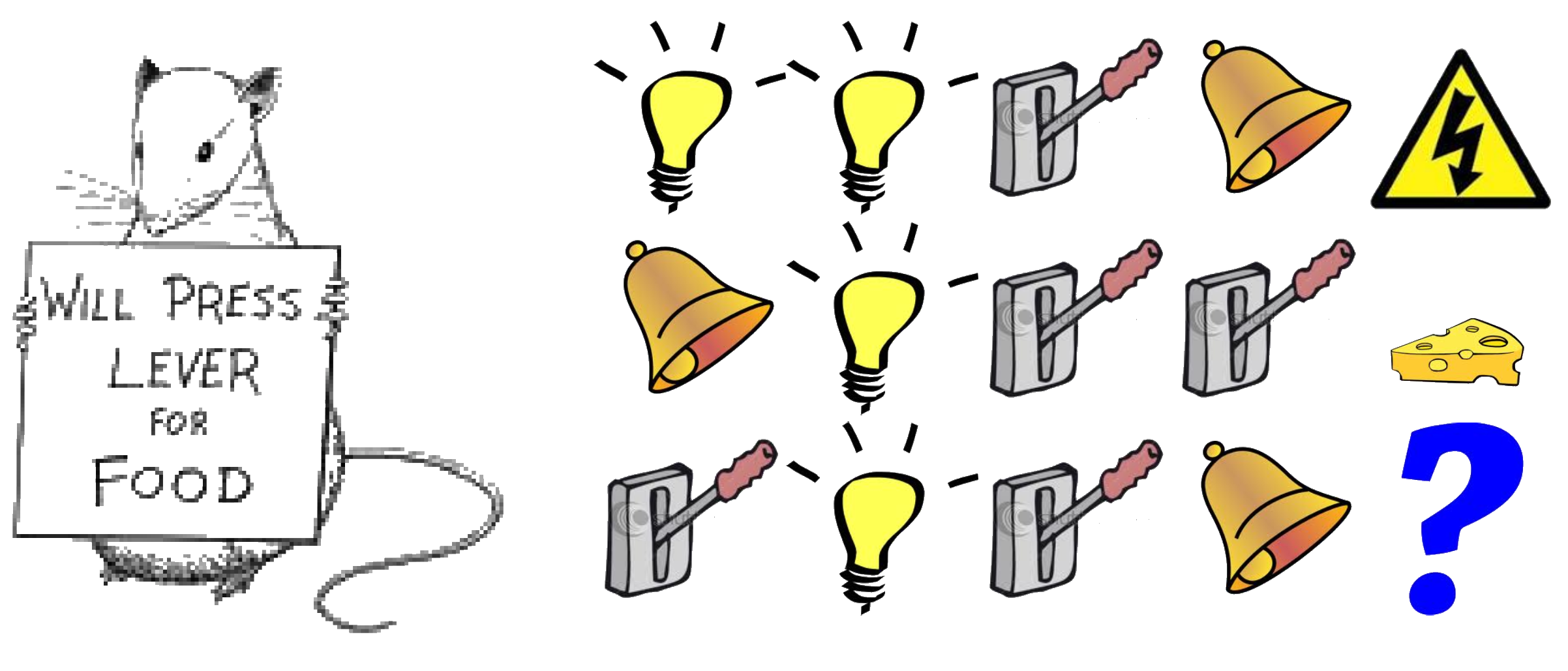
What if agent state = last \(n\) items in sequence?
What if agent state = counts for lights, bells and levers?
Example: Gridworld
- states = cells
- actions = up, down, left, right, 10% chance of 90\(\degree\) error
- reward \(r(s) = 0\) for non-terminal nodes
- discount factor \(\gamma = 0.9\)