06 Model-based RL (Value Iteration & MCTS)
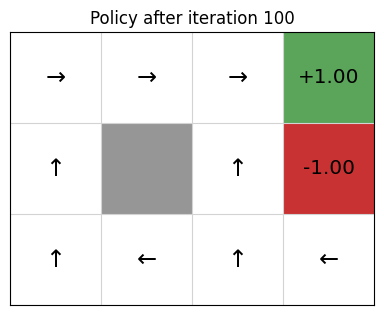
Example: Gridworld
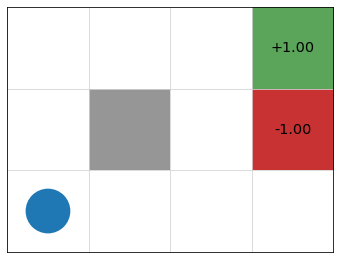
- states = cells
- actions = up, down, left, right, 10% chance of 90\(\degree\) error
- reward \(r(s) = 0\) for non-terminal nodes
- discount factor \(\gamma = 0.9\)
Example: GridWorld
\[ V_1(s) = \max\limits_{a \in A(s)} \sum\limits_{s' \in S} P_a(s' \mid s) R(s) + \gamma \underbrace{V_0(s')}_{0}] \]
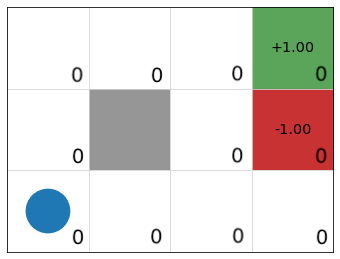
\(V_0\)
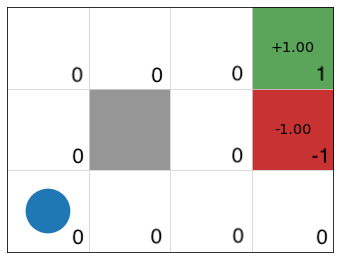
\(V_1\)
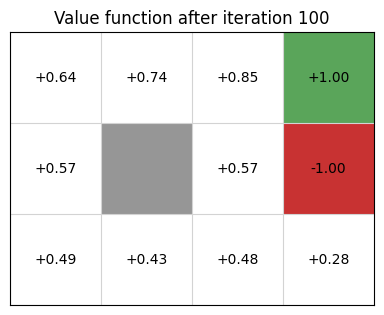
Example continued
\[ V_2(s) = \max\limits_{a \in A(s)} \sum\limits_{s' \in S} P_a(s' \mid s) [R(s) + \gamma V_1(s')] \]
\(V_1\)
\(V_2\)
Policy Extraction
Once value function stabilizes, we extract a deterministic policy as
\[ \pi(s) = \text{argmax}_{a \in A(s)} \sum\limits_{s' \in S} P_a(s' \mid s)\ [R(s,a,s') + \gamma\ V(s')] \]
Model-based methods
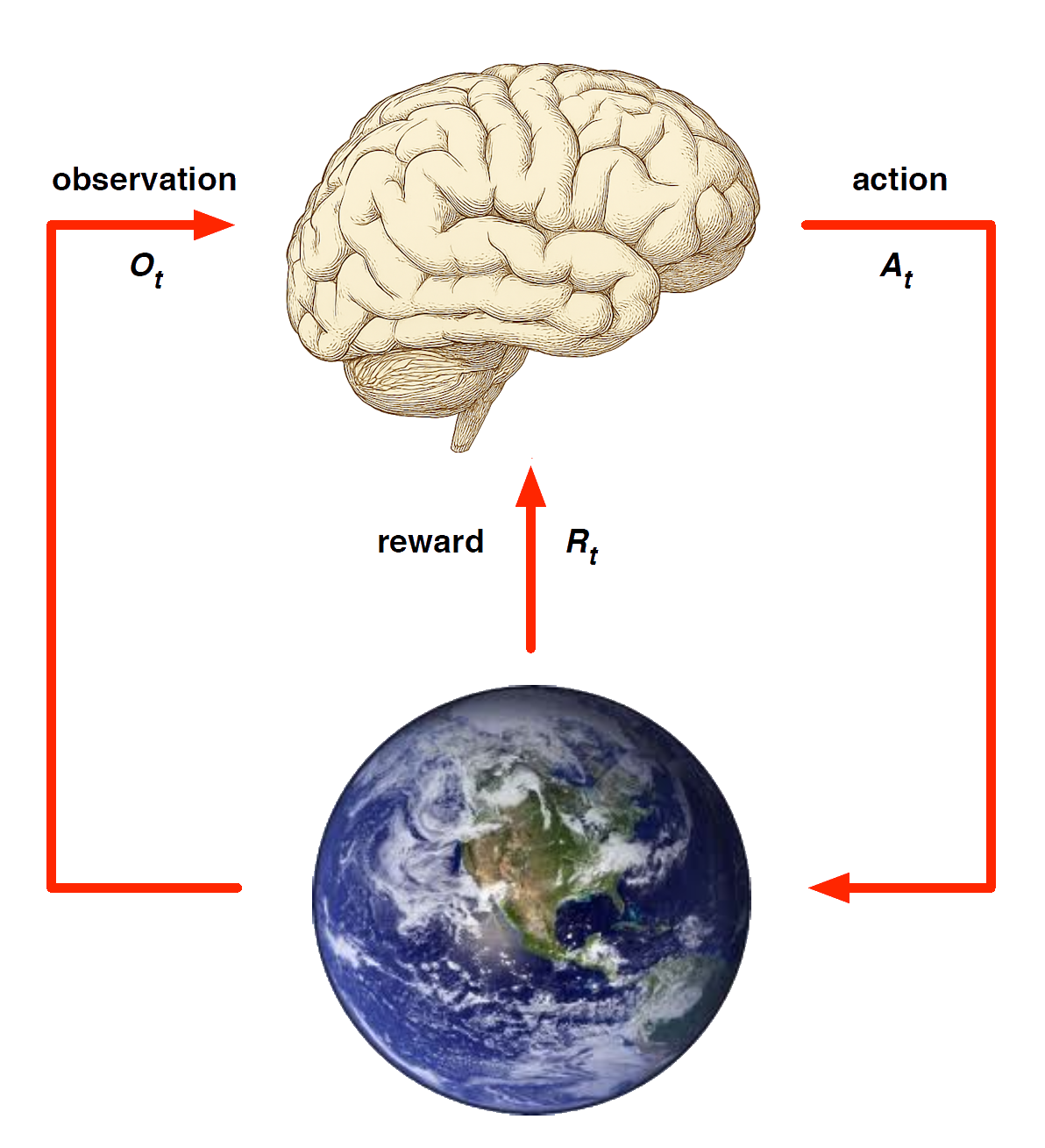
Replace real world with the agent’s (simulated) model of the environment
Supports rollouts (lookaheads) under imagined actions to reason about what value function will be, without further environment interaction
ExpectiMax Trees
Monte Carlo Tree search (MCTS) is based on representing MDPs as ExpectiMax trees that unfold as agents take actions.
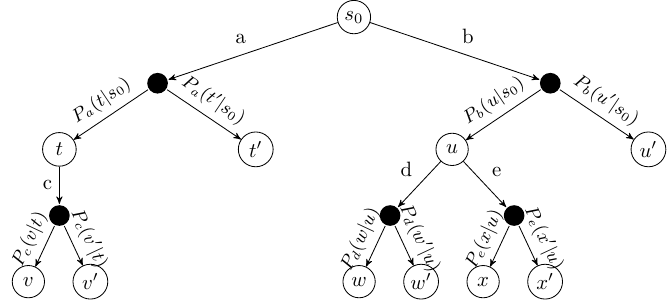
Note: state nodes are full histories