03 Heuristic Search
Route-Finding

Straight-line distances from Bucharest to

Relaxation in Route-Finding?
Straight-line distances from Bucharest to
How do we derive straight-line distances in route-finding by relaxation?:
- Problem \(\mathcal{P}\)?: Route finding.
- Simpler problem \(\mathcal{P}^{\prime}\)?:
- Route finding for birds.
- Perfect heuristic \(h^{\prime *}\) for \(\mathcal{P}^{\prime}\)?:
- Straight-line distance.
- Relaxation Transformation \(r\)?:
- Transform instances of \(\mathcal{P}\) into instances of \(\mathcal{P}^{\prime}\) by pretending you are a bird.
The 8-Puzzle

- Action: move(X,Y)
- Pre: blank(Y), adjacent(X,Y)
- Add: blank(X)
- Del: blank(Y)
Relaxation in the 8-Puzzle?
A perfect heuristic \(h^*\) for \(\mathcal{P}\): Actions = A tile can move from square \(X\) to square \(Y\) if \(X\) is adjacent to \(Y\), adjacent(X,Y), and \(Y\) is blank, i.e. blank(Y).
How do we derive the Manhattan distance heuristic?:
- \(\mathcal{P}^{\prime}\): Actions = A tile can move from square \(X\) to square \(Y\) if \(X\) is adjacent to \(Y\).
How do we derive a heuristic which counts the number of misplaced tiles?:
\(\mathcal{P}^{\prime}\): Actions = A tile can move from square \(X\) to square \(Y\).
\(h^{\prime *}\) (respectively \(r\)) in both: optimal cost in \(\mathcal{P}^{\prime}\) (respectively use different actions).
Here, Manhattan distance = 18 and misplaced tiles = 8.
Travelling Salesman Problem (TSP) in Australia

Propositions \(P\): \(\mathit{at}(X)\) for \(X \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\); \(\mathit{v}(X)\) for \(x \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\).
Actions \(a \in A\): \(\mathit{drive}(X,Y)\) where \(X,Y\) is a road; \(\mathit{pre}_a = \{\mathit{at}(X)\}\), \(\mathit{add}_a = \{\mathit{at}(Y), \mathit{v}(Y)\}\), \(\mathit{del}_a = \{\mathit{at}(X)\}\).
Initial state \(I\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(\mathit{Sy})\).
Goal \(G\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(X)\) for all \(x\).
“Goal-Counting” Relaxation for TSP in Australia?
Propositions \(P\): \(\mathit{at}(X)\) for \(X \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\); \(\mathit{v}(X)\) for \(X \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\).
Actions \(a \in A\): \(\mathit{drive}(X,Y)\) where \(X,Y\) is a road; \(\mathit{pre}_a = \{\mathit{at}(X)\}\), \(\mathit{add}_a = \{\mathit{at}(y), \mathit{v}(y)\}\), \(\mathit{del}_a = \{\mathit{at}(X)\}\).
Initial state \(I\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(\mathit{Sy})\).
Goal \(G\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(X)\) for all \(X\).
Let’s act as if we can achieve each goal directly:
Problem \(\mathcal{P}\): All STRIPS planning tasks; Simpler problem \(\mathcal{P}^{\prime}\): All STRIPS planning tasks with empty preconditions and deletes; Perfect heuristic \(h^{\prime *}\) for \(\mathcal{P}^{\prime}\): Optimal plan cost \((= h^{\prime *})\).
Transformation \(r\) ?:
- Drop the preconditions and deletes.
Heuristic value here?:
- 4 (since each applicable drive action can be treated as achieving one visit fact directly, and since deletes are ignored, a relaxed plan can achieve the goal in 4 actions).
Relaxations: Illustration (Example: Route-finding)

Problem \(\mathcal{P}\): Route finding
Simpler problem \(\mathcal{P}^{\prime}\):
- Route finding for birds
Perfect heuristic \(h^{\prime *}\) for \(\mathcal{P}^{\prime}\):
- Straight-line distance.
Transformation \(r\)?:
- Pretend you are a bird
Native Relaxations: Illustration (Example: Goal-counting)

Problem \(\mathcal{P}\): All STRIPS planning tasks.
Simpler problem \(\mathcal{P}^{\prime}\): All STRIPS planning tasks with empty preconditions and deletes
Perfect heuristic \(h^{\prime *}\) for \(\mathcal{P}^{\prime}\): Optimal plan cost \(= h^{*}\)
Transformation \(r\)?:
- Drop the preconditions and deletes.
Relaxation in Route-Finding: Properties?
Straight-line distances from Bucharest to
Assume relaxation \(\mathcal{R} = (\mathcal{P}^{\prime}, r, h^{\prime *})\): Straight-line distances (you are pretending to be a bird!)
Native?:
- No, birds don’t do route-finding (their flight is equivalent to trivial maps with direct routes between everywhere.)
Efficiently constructible?:
- Yes (pretend you are a bird).
Efficiently computable?:
- Yes (measure straight-line distance).
Relaxation in the 8-Puzzle: Properties?
Relaxation \(\mathcal{R} = (\mathcal{P}^{\prime}, r, h^{\prime *})\): Use more generous actions rule to obtain Manhattan distance.
Native?:
- No, with the modified rules, as it’s not the “same puzzle” anymore.
Efficiently constructible?:
- Yes (exchange action set).
Efficiently computable?:
- Yes (count misplaced tiles/sum up Manhattan distances).
Goal-Counting Relaxation in TSP: Properties?
Propositions \(P\): \(\mathit{at}(X)\) for \(X \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\); \(\mathit{v}(X)\) for \(X \in \{\mathit{Sy}, \mathit{Ad}, \mathit{Br}, \mathit{Pe}, \mathit{Da}\}\).
Actions \(a \in A\): \(\mathit{drive}(X,Y)\) where \(X,Y\) have a road; \(\mathit{pre}_a = \{\mathit{at}(X)\}\), \(\mathit{add}_a = \{\mathit{at}(y), \mathit{v}(Y)\}\), \(\mathit{del}_a = \{\mathit{at}(X)\}\).
Initial state \(I\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(\mathit{Sy})\).
Goal \(G\): \(\mathit{at}(\mathit{Sy}), \mathit{v}(X)\) for all \(X\).
Relaxation \(\mathcal{R} = (\mathcal{P}^{\prime}, r, h^{\prime *})\): Remove preconditions and deletes, then use \(h^*\).
Native?:
- Yes: planning with empty preconditions and deletes is a special case of planning (i.e. a sub-class of ).
Efficiently constructible?:
- Yes: drop preconditions and deletes.
Efficiently computable?:
- No, Optimal relaxed planning is still \(\mathit{NP}\)-hard (MINIMUM COVER of goal set by add lists).
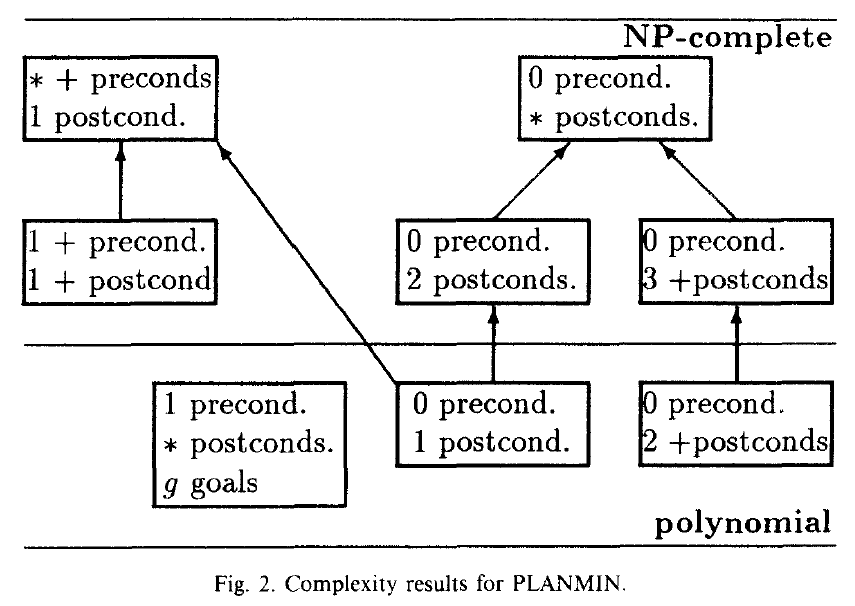
Even if the precondition \(at()\) is dropped, resulting in \(0\) preconditions, with the \(2\) postconditions \(at(Y)\) and \(v(Y)\)), the problem complexity is still NP-complete, i.e. not effectively computable.
*Figure from Bylander, 1994 The Computational Complexity of Propositional STRIPS Planning, Artificial Intelligence Journal, Volume 69, pp 165–204
How to Relax During Search: Diagram
Using a relaxation \(\mathcal{R} = (\mathcal{P}^{\prime}, r,h^{\prime *})\) during search:

\(\Pi_s\): is problem \(\Pi\) with initial state replaced by \(s\)
- i.e., \(\Pi = (F,A,c,I,G)\) changed to \((F,A,c,s,G)\) (initial sate \(s\))
This is the task of finding a plan for search state \(s\)
- We will be using this notation in the course
How to Relax During Search: Logistics Problem

- Initial state \(I\): \(AC\)
- \(AC\) is the state encoding used here, that denotes that truck is at \(A\) and package is at \(C\). If the package is loaded on the truck it is at \(T\).
- Goal \(G\): \(AD\)
- The goal is for the truck to take package to D from C, then return to A
- Actions \(A\): \(drXY\) (drive from \(X\) to \(Y\)), \(loX\) (load package \(X\)), \(ulX\) (unload \(X\))
- Each action also has corresponding \(pre\), \(add\) & \(del\)
How to Relax During Search: Goal-Counting?

























How to Relax During Search: Ignoring Deletes?


























