11 Deep Learning & Tree Search - AlphaGo, AlphaZero & MuZero (Advanced Topic)
This Module
Last Module: Actor critic (policy gradient)
Previous Module: Value function approximation using deep learning
This Module: Combining deep learning & tree search
AlphaGo
The Game of Go (Revisited)
The ancient oriental game of Go is \(2,500\) years old
Considered to be one of the hardest classic board games
Considered a grand challenge task for AI (John McCarthy)
- Traditional game-tree search has failed in Go

Rules of Go
Usually played on 19x19, also 13x13 or 9x9 board
Simple rules, complex strategy:
Black and white place down stones alternately
Surrounded stones are captured and removed
The player with more territory wins the game


Position Evaluation in Go
How good is a position \(s\)?
- Reward function (undiscounted):
\[ \begin{align*} R_t & = 0 \quad \text{for all non-terminal steps } t < T\\[0pt] R_T & = \begin{cases} 1 & \text{if Black wins} \\ 0 & \text{if White wins} \end{cases} \end{align*} \]
Policy \(\pi = \langle \pi_B, \pi_W \rangle\) that selects moves for each player
Value function (how good is position \(s\), black chooses strategy that maximises its chance of winning, assuming White tries to minimise it):
\[ \begin{align*} v_\pi(s) & = \mathbb{E}_\pi \left[ R_T \mid S = s \right] = \mathbb{P}[ \text{Black wins} \mid S = s ]\\[0pt] v_*(s) & = \max_{\pi_B} \min_{\pi_W} v_\pi(s) \end{align*} \]
AlphaGo - Core Idea
First system to combine deep learning and tree search for superhuman play, in the domain of Go only.
The pipeline integrates:
- Supervised learning from histories of expert games from human players
- Reinforcement learning is achieved through self-play using a pre-programmed simulator which is used to capture the rules of the game.
- Monte Carlo Tree Search (MCTS) is then guided by the neural networks
Reference: Silver, D. et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484–489.
AlphaGo - Architecture
Architecture: AlphaGo utilises two policy networks and one value network.
So three neural networks are used to integrate
- Policy network 1: supervised learning trained on human expert moves,
- Policy network 2: reinforcement learning obtained by self-play, and
- Value network: a separate network trained to predict the probability of winning from a position, using self-play games generated by Policy network 2.
Monte Carlo Tree Search (MCTS) then uses Policy network 1 for move priors, and the Value network for position evaluation, and a separate fast rollout policy for playouts.
AlphaGo - Neural networks & Loss Calculation
| Neural Network | Description |
|---|---|
| Policy Network (\(\pi_1\)) | Trained supervisedly on human moves; 13-layer CNN (Go board 19×19 × 48 planes) |
| Policy Network (\(\pi_2\)) | Refined by self-play RL (same architecture) |
| Value Network (\(v\)) | 13-layer CNN + 2 fully connected layers; outputs scalar win probability \(v(s)\) |
Training objective for policy network loss (\(\mathcal{L_{\pi}}\), the negative log likelihood) and value network loss (\(\mathcal{L_v}\)): \[ \mathcal{L}_\pi = -\log \pi_\theta(a^\ast|s), \qquad \mathcal{L}_v = (v_\phi(s)-z)^2 \] where \(a^\ast\) is the desired target move and \(z \in \{-1,+1\}\) is the game outcome and \(\phi\) are the network parameters.
AlphaGo - MCTS Planning Integration
Monte Carlo Tree Search (MCTS) uses:
Policy prior \(\pi_\theta(a|s)\) from policy network \(\pi_1\) (parameters \(\theta\)) \(\rightarrow\) biases search toward likely moves
Value estimate \(v_\phi(s)\) from value network \(v\) (parameters \(\phi\)) \(\rightarrow\) evaluate leaves
Move selection at root is executed via separate rollout policy \(\pi_{MCTS}\):
\[ \pi_{\text{MCTS}}(a|s_0)\propto N(s_0,a)^{1/\tau} \]
- Where \(N\) is the visit count of state-actions pairs for taking action \(a\) for simulations from the root state \(s_0\). \(\tau\) is a temperature parameter that controls the level of exploration versus exploration when converting visit counts into a probability distribution.
The fast rollout policy is also trained from human expert moves, like the supervised policy network, but it is made deliberately much simpler and faster using a linear softmax of small pattern features, rather than the deep convolutional policy network.
AlphaGo - Self Play
Once policy network \(\pi_2\) is trained through reinforcement learning (it is initialised from \(\pi_1\)), AlphaGo uses it to play millions of games against itself.
- Each game produces pairs \((s, z)\): \((s_t,z_t)\) where \(z \in \{-1,+1\}\) is the game outcome.
These pairs are then used to train the Value network \(v_{\phi}(s_t)\) via regression:
\[ \min_{\phi} \; \bigl(v_{\phi}(s_t) - z_t\bigr)^2 \]
So the value network learns to predict who will win from any board position that strong play (i.e., \(\pi_2\)) would reach.
Achieved 4-1 win versus Lee Sedol (2016)
AlphaGo - Limitations
AlphaGo is limited by requiring the following:
Histories of expert human play are required specific to the game of Go, and
A hand-crafted rollout policy must be specified for the game of Go (e.g. preferring moves that capture stones, etc.).
AlphaZero
AlphaZero - Core idea: Unified Self-Play RL
Extends AlphaGo to a wide range of games \(\rightarrow\) Go, Chess, Shogi
Removes human data and hand-crafted rollout policy
Fully self-play training loop
Reference: Silver, D. et al. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144.
Question: AlphaZero - How does it work?
Architecture: AlphaZero removes the need for human data and the hand-crafted rollout policy
- How does AlphaZero setup the neural networks to achieve a fully self-play training loop?
AlphaZero - Learning & Planning Loop
\[ \text{Network} \Rightarrow \text{MCTS} \Rightarrow \text{Self-play games} \Rightarrow \text{Network update} \]
MCTS: ~800 simulations per move
Network: ResNet (residual neural network) trained via SGD (Stochastic Gradient Descent) on MCTS targets
Unified architecture simplified training → superhuman performance across games
AlphaZero - Neural network and objective
Single residual CNN shared by policy + value
20 or 40 ResNet blocks, 256 filters, BatchNorm + Rectified Linear Circuit (ReLU)
Input: stack of board planes (19×19×N)
Heads:
Policy head: 1 conv + 1 FC \(\rightarrow\) softmax over legal moves
Value head: 1 conv + 2 FC \(\rightarrow\) scalar \(v_\theta(s)\)
Loss: \[ \mathcal{L}(\theta)= (z-v_\theta(s))^2 -\pi_{\text{MCTS}}^\top\!\log\pi_\theta +c\|\theta\|^2 \]
MuZero
MuZero - Core idea: Learning to Plan Without Rules
AlphaZero still needs explicit game rules, which it accesses using a pre-programmed game simulator internal to the agent.
MuZero can learn a wide range of games without knowing the rules of the game.
MuZero learns a latent model of dynamics for planning from experience by interaction with the environment.
It uses the same MCTS framework, but search happens in latent space
Reference: Schrittwieser, J. et al. (2020). Mastering Atari, Go, chess and shogi by planning with a learned model. Nature, 588, 604–609.
MuZero - Results and Significance
| Domain | Training time to superhuman level | Benchmark / Opponent | Notes |
|---|---|---|---|
| Chess | \(\approx\) 4 hours (on 8 TPUv3 pods) | Stockfish | Surpassed world-champion chess engine performance |
| Shogi | \(\approx\) 2 hours | Elmo | Surpassed leading professional Shogi engine |
| Go | \(\approx\) 9 hours | AlphaZero / KataGo | Matched AlphaZero’s superhuman play using only learned dynamics |
| Atari (57 games) | ~200M frames | Rainbow / IMPALA | Exceeded or matched best model-free RL baselines across games |
Summary of AlphaGo, AlphaZero, and MuZero Evolution
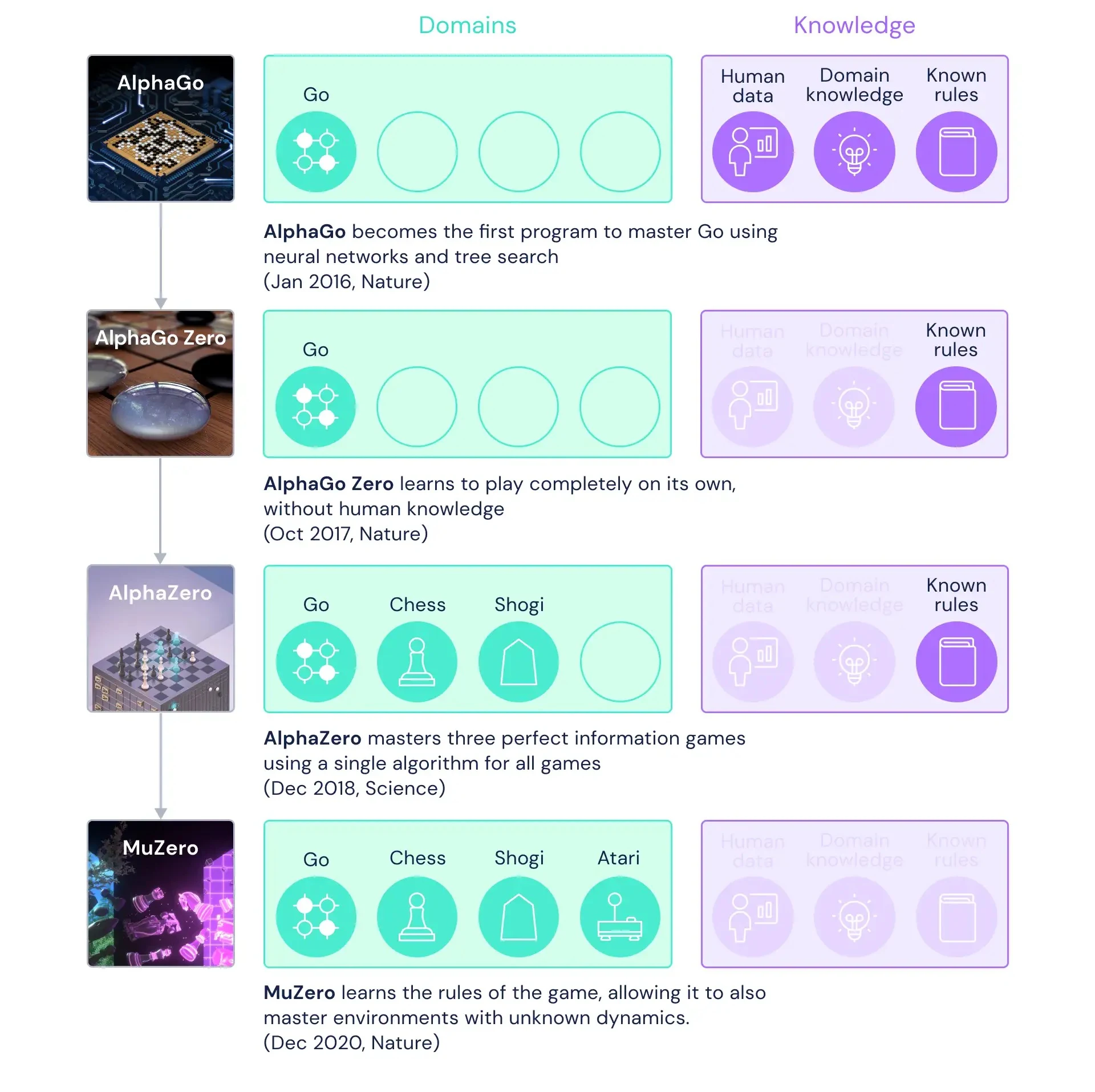
Figure reproduced from: https://deepmind.google/blog/muzero-mastering-go-chess-shogi-and-atari-without-rules/
Reading - DeepMind article on AlphaGo, AlphaZero, and MuZero

The following article is by DeepMind on the progression from AlphaGo, AlphaZero to MuZero: https://deepmind.google/blog/muzero-mastering-go-chess-shogi-and-atari-without-rules/
Question: MuZero - How does it work?
Architecture: MuZero learns a latent model of the dynamics of how to play Go, without the need to specify any of the rules.
- How does MuZero setup the neural network to achieve a training loop than learns without rules?
MuZero - Neural networks (3)
| Neural Network | Function | Notes |
|---|---|---|
| Representation \(h_\theta\) | Observation \(\rightarrow\) latent state \(s_0\) (learns (latent) state representation) | 6 ResNet blocks for Atari (pixels \(\rightarrow\) latent) |
| Dynamics \(g_\theta\) | Predicts \(s_{t+1},r_{t+1}\) from \((s_t,a_t)\) (learns model) | Small conv stack + reward head |
| Prediction \(f_\theta\) | Outputs policy \(p_t\) and value \(v_t\) from \(s_t\) | Two heads (softmax policy, scalar value) |
MuZero — TD-Style Learning (Bootstrapped Returns)
Unlike AlphaZero (which uses full-episode Monte Carlo targets),
MuZero trains its value network using n-step bootstrapped (TD) returns
For each step (t), the target value is: \[ \hat{v}_t = \sum_{i=0}^{n-1} \gamma^i r_{t+i} + \gamma^n v_\theta(s_{t+n}) \]
Combines observed rewards and bootstrapped value from the predicted future state
Allows credit assignment across long horizons without waiting for episode termination
MuZero minimises a combined loss: \[ \mathcal{L} = \sum_k \Big[ (v_k - \hat v_k)^2 + (r_k - \hat r_k)^2 - \pi_k^\top \log p_k \Big] \]
Value loss: TD-style bootstrapped error
Reward loss: immediate reward prediction
Policy loss: cross-entropy with MCTS visit-count distribution
TD bootstrapping makes MuZero more sample efficient than AlphaZero
Planning (MCTS) provides strong policy/value targets; TD updates keep learning continuous
MuZero - Training and Integration
MCTS operates within the learned model:
\[s_{t+1},r_t=g_\theta(s_t,a_t)\]
Targets from MCTS train all three nets end-to-end
Loss: \[ \mathcal{L} =\sum_k\! \big[ (v_k-\hat v_k)^2 +(r_k-\hat r_k)^2 -\pi_k^\top\!\log p_k \big] \]
- Achieves AlphaZero-level play in Go/Chess/Shogi and strong Atari results from pixels
MuZero - Key Insights
- No rules given: MuZero learned dynamics, value, and policy purely from experience
- Unified algorithm: Same architecture and hyperparameters across all domains
- Planning efficiency: Performed Monte Carlo Tree Search (MCTS) entirely in latent space
- Sample efficiency: Achieved AlphaZero-level play within hours of self-play training
AlphaGo, AlphaZero & MuZero Comparison
| System | # of NNs | Architecture | Uses known rules? | Learns model? | Planning |
|---|---|---|---|---|---|
| AlphaGo | 2 (policy + value) | 13-layer CNNs | \(\checkmark\) | \(\text{✗}\) | MCTS with rules |
| AlphaZero | 1 (shared policy-value ResNet) | 20–40 ResNet blocks | \(\checkmark\) | \(\text{✗}\) | MCTS with rules |
| MuZero | 3 (\(h,g,f\) modules) | ResNet latent model | \(\text{✗}\) | \(\checkmark\) | MCTS in latent space |
Reading - AlphaGo, AlphaZero, and MuZero Papers
AlphaGo: Silver, D. et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484–489.
AlphaZero: Silver, D. et al. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144.
MuZero: Schrittwieser, J. et al. (2020). Mastering Atari, Go, chess and shogi by planning with a learned model. Nature, 588, 604–609.