Appendix (Additional Examples & Reference Material)
Example: Student MDP

Agent exerts control over MDP via actions, and goal is to find the best path through decision making process to maximise rewards
Example: State-Value Function for Student MDP

Bellman Expectation Equation for \(V^{\pi}\) (look ahead)

\[ v_\pi(s) = \sum_{a \in \mathcal{A}} \pi(a \mid s)\, q_\pi(s, a) \]
Bellman Expectation Equation for \(Q^{\pi}\) (look ahead)

\[ q_\pi(s, a) = \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{s s'}\, v_\pi(s') \]
Bellman Expectation Equation for \(v_{\pi} (2)\)
Bringing it together: agent actions (open circles), environment actions (closed circles)

\[ v_\pi(s) = \sum_{a \in \mathcal{A}} \pi(a \mid s) \left( \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{s s'} \, v_\pi(s') \right) \]
Bellman Expectation Equation for \(q_{\pi} (2)\)
The other way around: can do same thing for action values

\[ q_\pi(s, a) = \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{s s'} \sum_{a' \in \mathcal{A}} \pi(a' \mid s') \, q_\pi(s', a') \]
In both forms value function is (recursively) equal to reward of immediate state \(s\) + value \(s'\) (where you end up)
Example: Bellman Expectation Equation in Student MDP

Verify Bellman Equation to compute \(v_{\pi}(s)\) for \(s=C3\)
Example: Optimal Value Function for Student MDP

Gives us value function for each state \(s\) (not how to behave)
Example: Optimal Action-Value Function for Student MDP

Gives us best action, \(a\), for each state \(s\) (can choose)
Example: Optimal Policy for Student MDP

Red arcs (actions) represent optimal policy: picks highest \(q_\ast\)
Bellman Optimality Equation for \(v_\ast\) (look ahead)
The optimal value functions are recursively related by the Bellman optimality equations:

\[ v_\ast(s) = \max\limits_{a} q_\ast(s,a) \]
Working backwards using backup diagrams we get \(v_\ast(s)\) - best action over all policies taking max instead of average
Bellman Optimality Equation for \(Q^\ast\) (look ahead)

\[ q_\ast(s,a) = \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{ss'} \, v_\ast(s') \]
Considers where the environment might take us by averaging (looking ahead) and backing up (inductively)
Bellman Optimality Equation for \(V^* (2)\)
Bringing it together (two-step look ahead): agent actions (open circles), environment actions (closed circles)

\[ v_\ast(s) = \max\limits_{a} \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{ss'} \, v_\ast(s') \]
Bellman Optimality Equation for \(Q^* (2)\)

\[ q_\ast(s,a) = \mathcal{R}^a_s + \gamma \sum_{s' \in \mathcal{S}} \mathcal{P}^a_{ss'} \, \max\limits_{a'} q_\ast(s',a') \]
Determines \(Q^{\ast}\) reordering from environments perspective
Example: Bellman Optimality Equation in Student MDP

Compute \(v_{\ast}(s)\) for \(s=C1\) looking one step ahead (no environment actions in \(C1\))
Model-Free RL
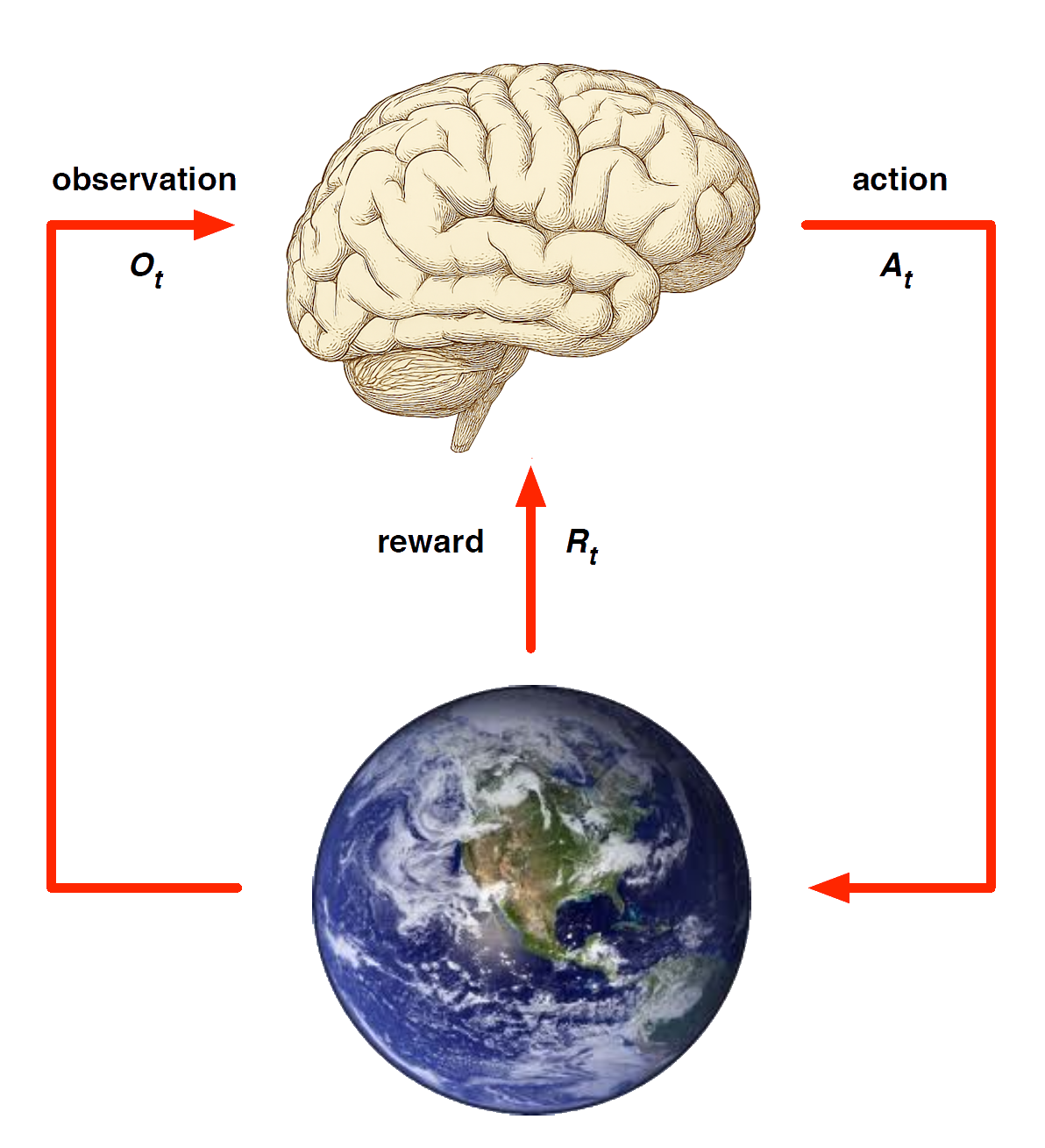
Model-Based RL
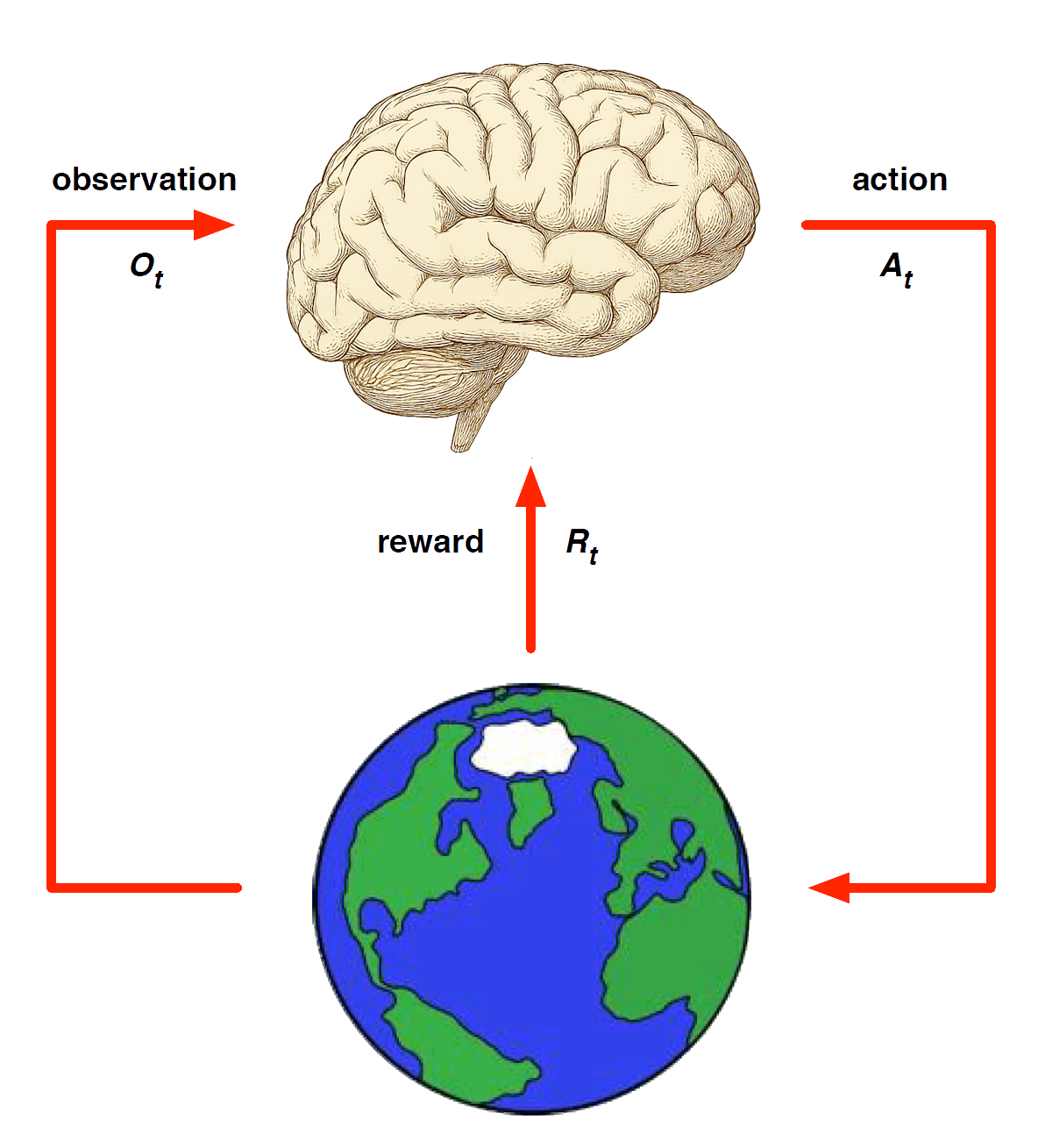
Replace real world with the agent’s (simulated) model of the environment
- Supports rollouts (lookaheads) under imagined actions to reason about what value function will be, without further environment interaction
Model-Based RL (2)

AB Example (Revisited) - Building a Model
Two states \(A,B\); no discounting; \(8\) episodes of experience
\(A, 0, B, 0\)
\(B, 1\)
\(B, 1\)
\(B, 1\)
\(B, 1\)
\(B, 1\)
\(B, 1\)
\(B, 0\)

We have constructed a table lookup model from the experience
Is Blocksworld Hard?

Blocksworld is Hard!
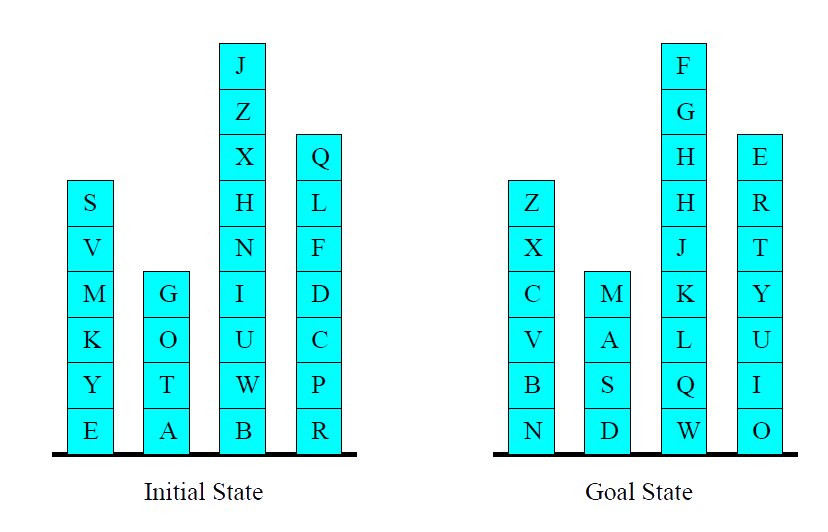
Why All the Fuss? Example Blocksworld

- \(n\) blocks, \(1\) hand.
- A single action either takes a block with the hand or puts a block we’re holding onto some other block/the table.
Least Squares Policy Iteration

Policy evaluation Policy evaluation by least-squares Q-learning
Policy improvement Greedy policy improvement
Chain Walk Example (More complicated random walk)

Consider the 50 state version of this problem (bigger replica of this diagram)
Reward \(+1\) in states \(10\) and \(41\), \(0\) elsewhere
Optimal policy: R (\(1-9\)), L (\(10-25\)), R (\(26-41\)), L (\(42, 50\))
Features: \(10\) evenly spaced Gaussians (\(\sigma = 4\)) for each action
Experience: \(10,000\) steps from random walk policy
LSPI in Chain Walk: Action-Value Function

LSPI in Chain Walk: Policy

Natural Policy Gradient—Parameterisation Invariant

- The black contours show level sets of equal performance \(J(\theta)\)
- The blue arrows show the ordinary gradient ascent direction for each point in parameter space (not orthogonal to the contours, behave irregularly across space)
- The red arrows are the natural gradient directions (ascent directions are orthogonal to contours and smoothly distributed)
- Natural gradient respects geometry of probability distributions—it finds steepest ascent direction measured in policy (distributional) space, not raw parameter space
Natural Actor Critic in Snake Domain

- The dynamics are nonlinear and continuous—a good test of policy gradient methods.
Natural Actor Critic in Snake Domain (2)

- The geometry of the corridor causes simple gradient updates to oscillate or diverge, but natural gradients (which adapt to curvature via the Fisher matrix independent of parameters) make stable, efficient progress.